the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 20 Apr 2023
| 20 Apr 2023
DQPB: software for calculating disequilibrium U–Pb ages
Timothy Pollard
Jon Woodhead
John Hellstrom
John Engel
Roger Powell
Russell Drysdale
Initial radioactive disequilibrium amongst intermediate nuclides of the U decay chains can have a significant impact on the accuracy of
U–Pb ages, especially in young samples. For samples that can reasonably be assumed to have attained radioactive equilibrium at the
time of analysis, a relatively straightforward correction may be applied. However, in younger materials where this assumption is unreasonable, it is necessary to replace the familiar U–Pb age equations with more complete expressions that account for growth and decay of intermediate nuclides through time. DQPB is software for calculating U–Pb ages while accounting for the effects of radioactive disequilibrium among intermediate nuclides of the U decay chains. The software is written in Python and distributed as both a pure Python package and a stand-alone graphical user interface (GUI) application that integrates with standard Microsoft Excel spreadsheets. The software implements disequilibrium
U–Pb equations to compute ages using various approaches, including concordia intercept ages on a Tera–Wasserburg diagram,
U–Pb isochron ages, ages based on single aliquots, and 207Pb-corrected ages. While these age-calculation
approaches are tailored toward young samples that cannot reasonably be assumed to have attained radioactive equilibrium at the time of analysis,
they may also be applied to older materials where disequilibrium is no longer analytically resolvable. The software allows users to implement a
variety of regression algorithms based on both classical and robust statistical approaches, compute weighted average ages and construct
customisable, publication-ready plots of U–Pb age data. The regression and weighted average algorithms implemented in DQPB may also be applicable to other (i.e. non-U–Pb) geochronological datasets.
- Article
(2242 KB) - Full-text XML
-
Supplement
(2573 KB) - BibTeX
- EndNote





With the exception of major uranium-bearing phases, rocks and minerals younger than a few million years were once considered virtually inaccessible to U–Pb methods owing to difficulties inherent in measuring the small quantities of radiogenic Pb generated over such short time periods (Getty and DePaolo, 1995). However, analytical advances over the past two decades, including improvements in pre-screening (Rasbury and Cole, 2009), sample preparation (e.g. Engel et al., 2020) and mass spectrometry (e.g. Getty and DePaolo, 1995; Woodhead et al., 2006; Sakata et al., 2014), have opened up the possibility of accurately and precisely dating materials as young as the Late Pleistocene age. These methodologies are now widely applied to radiogenic Pb-rich minerals including zircon (e.g. Paquette et al., 2019), as well as common Pb-rich materials such as carbonates (e.g. Richards et al., 1998), using both bulk and laser ablation (LA) or secondary ion mass spectrometry (SIMS) sampling techniques. In addition to analytical challenges in applying the U–Pb geochronometer to such young materials, another major issue lies in the need to accurately account for the effects of initial radioactive disequilibrium among intermediate nuclides of the U-series decay chains. For older samples, the effects of initial disequilibrium are often small relative to the precision of individual age determinations, but in younger materials, failure to correct for these effects can lead to large inaccuracies in final calculated ages (Ludwig, 1977; Schärer, 1984).
Secondary carbonates, such as speleothems, are well-known to be deposited out of radioactive equilibrium with respect to , reflecting the ratios in the parent waters from which they form (Osmond and Cowart, 1992). Moreover, the insolubility of Th and Pa in these parent waters leads to their near exclusion from newly precipitated carbonate, causing an additional component of disequilibrium (Richards et al., 1998). On the other hand, igneous minerals formed in high-temperature environments tend to be crystallised at, or very close to, radioactive equilibrium with respect to , but out of equilibrium with respect to Th and Pa (Schoene, 2014). For example, minerals such as zircon tend to crystalise with ratios below radioactive equilibrium and initial ratios in excess of radioactive equilibrium (Schmitt, 2007), whereas Th-rich phases, such as monazite, tend to crystalise with ratios in excess of radioactive equilibrium (Schärer, 1984). Over time, any initial excess or deficiency of intermediate nuclides gradually decreases as the U decay chains evolve toward radioactive equilibrium, eventually reaching a point after about 6–8 half-lives where disequilibrium effects are too small to be measured using current analytical techniques. For carbonates, this is typically 1.5 to 2 Ma for both and , since evolution of 230Th toward equilibrium is constrained to follow that of the preceding nuclide 234U. For high-temperature minerals formed in equilibrium with respect to but out of equilibrium with respect to , this age limit is typically closer to ∼ 0.5 Ma.
There are two main approaches employed to account for the effects of radioactive disequilibrium on U–Pb ages. The first of these is applicable to samples that can reasonably be assumed to have attained radioactive equilibrium at the time of analysis. This involves correcting isotope ratios (where * denotes radiogenic Pb formed in situ by decay of U) for any excess or deficiency of intermediate nuclides relative to their radioactive equilibrium values (Schärer, 1984; Parrish, 1990). In a closed system, each daughter nuclide in initial excess or deficiency of equilibrium will cause an equivalent over or under abundance of Pb* once radioactive equilibrium is established (Mattinson, 1973). Therefore, it is possible to apply a relatively straightforward correction by adding or subtracting this excess or deficit of Pb*, provided the initial disequilibrium state is known or can be reliably estimated. Ages can then be computed using the regular U–Pb equations that disregard in-growth and decay of intermediate nuclides.
However, for younger samples, which cannot be assumed to be in a state of radioactive equilibrium at the time of analysis, it is necessary to replace the familiar U–Pb age equations with more complete expressions that can account for the growth and decay of intermediate nuclides through time. Equations of this form were first presented for the U–Pb system by Ludwig (1977) based on Bateman's (1910) general solution to differential equations that describes time evolution of radionuclides for an arbitrary linear decay chain. Later, Wendt and Carl (1985) presented an alternative version of these equations that includes some simplifying assumptions, whilst Guillong et al. (2014) provide a similar equation that accounts for disequilibrium in a single intermediate nuclide only1. These “disequilibrium U–Pb” equations are general and can also be applied to older samples that have, in a practical sense, attained radioactive equilibrium at the time of analysis. On the other hand, inappropriate use of the Pb*-correction approach described above can lead to large over- or under-correction, and thus inaccuracy in calculated ages, over timescales similar to those in which analytically resolvable disequilibrium persists (Fig. 1).
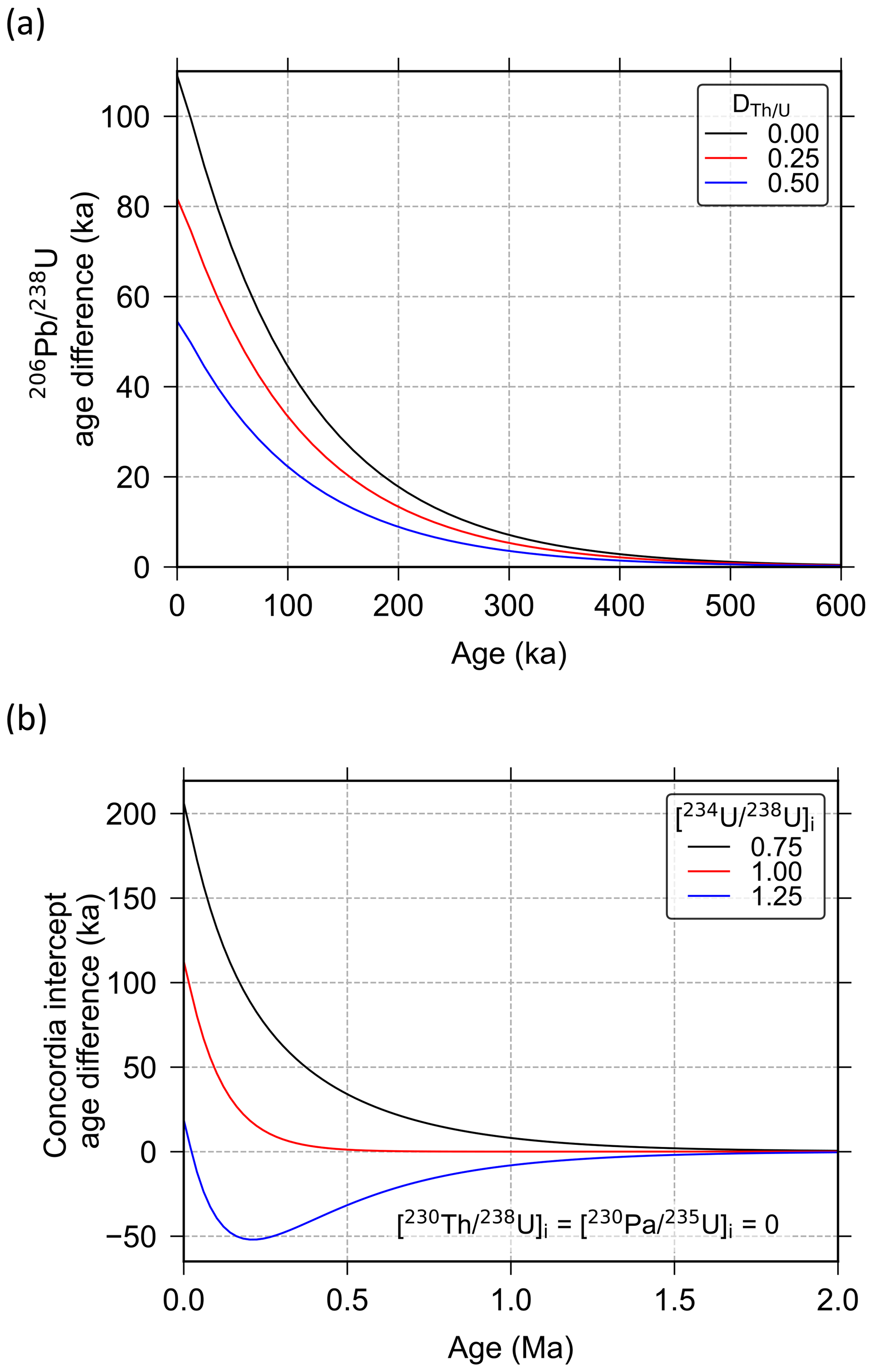
Figure 1Comparison of U–Pb ages calculated using two different approaches: (i) ages corrected for disequilibrium assuming radioactive equilibrium has been established at the time of analysis and (ii) ages calculated using the more accurate disequilibrium U–Pb equations that account for growth and decay of intermediate nuclides through time (e.g. Eqs. 1 and 7). Age difference is given as age calculated via approach (i) (assumed equilibrium at time of analysis) minus age calculated via approach (ii) (more accurate approach). The top panel (a) shows a comparison of zircon ages calculated assuming various values (where denotes the ratio of mineral–melt partition coefficients). The bottom panel (b) shows a comparison of Tera–Wasserburg concordia intercept ages for carbonate samples assuming various initial [] values (where square brackets denote activity ratios).
As these more complete disequilibrium U–Pb equations are rather cumbersome to implement compared to the conventional U–Pb age
equations, they are typically handled using specialised software or in-house computer code. Various approaches have been devised to achieve
this. Isoplot (Ludwig, 2012) may still be the most widely used software in geochronology and contains built-in functions based on Ludwig (1977) that can be used to calculate disequilibrium U–Pb ages as part of a spreadsheet-based approach. However, this has a number of limitations. Firstly, Isoplot, which is distributed as an Excel add-in, is no longer being maintained and is incompatible with recent versions of Excel. Secondly, the Isoplot licensing status is ambiguous, and so it is unclear if the source code can be modified or extended, for example, to produce plots of disequilibrium U–Pb age data. Thirdly, numerical computing and plotting within the Excel environment is limited. More recently, other software packages for handling disequilibrium U–Pb age data have been developed (Engel et al., 2019), or are in the developmental stage (additions to the IsoplotR package of Vermeesch, 2018). However, this former solution runs on proprietary software that is not widely used in geochronology, and the latter is not yet documented within the peer-review literature and does not currently propagate disequilibrium correction uncertainties.
Here we introduce DQPB, a software package for calculating disequilibrium U–Pb ages. DQPB implements the
disequilibrium U–Pb equations outlined below to compute ages using approaches that are suited to various young sample types. The
following sections outline software functionality and discuss approaches that are implemented for age calculation, error propagation, linear
regression, weighted average calculations and plotting.
DQPB is written in Python, an interpreted, high-level, general-purpose programming language that is rapidly gaining popularity within the geosciences. DQPB is available as both a regular Python package and a stand-alone application that does not require users to have a separate Python distribution pre-installed (see Sect. 8 for further details). Python offers several advantages as a language for
scientific software development, including its open-source status, well-equipped libraries of functions and routines for scientific computing, and relatively easy-to-read syntax (e.g. Oliphant, 2007). Being a general-purpose language, Python also offers significant advantages in
developing stand-alone graphical user interface (GUI) applications when compared to “domain-specific” scientific languages such as MATLAB
and R.
DQPB is built on the core Python scientific computing libraries NumPy (Harris et al., 2020), SciPy (Virtanen et al., 2020) and
Matplotlib (Hunter, 2007). It also takes advantage of PyQt to provide a modern GUI on macOS and Windows and xlwings to facilitate integration with Microsoft Excel. This allows users to select data from an open Excel spreadsheet, perform calculations via the graphical interface and have results (both numeric and figures) output to the same spreadsheet once computations are complete. In this way, it emulates the ease of use of the popular Isoplot programme (Ludwig, 2012). As is common practice with open-source software, all Python source code is
available for viewing, download and modification via an online code repository (see Sect. 8).
DQPB employs the equations of Ludwig (1977) to calculate U–Pb ages and plot disequilibrium age data. These equations were initially derived by Ludwig from a form of Bateman's (1910) solution that assumes zero initial abundance of all intermediate daughter nuclides and independently considers in-growth of Pb* from decay of the primordial parent and each preceding intermediate nuclide in the decay series (see also Ivanovich and Harmon, 1992; Neymark et al., 2000). These separate components are then summed, or “superposed” (Bateman, 1910), to obtain the total quantity of Pb* as a function of age, t.
Following this approach for the 238U decay chain, and ignoring intermediate nuclides with a half-life less than or equal to that of 210Pb (i.e. ∼ 22 a), results in an equation of the following form:
where , and each term represents in-growth from the primordial parent (subscript 1) and initial abundances of each preceding intermediate daughter nuclide in the decay chain (subscripts > 1). In full, these individual components are
where square brackets denote activity ratios; i denotes initial ratio; and c, h, and p are Bateman coefficients given by Eq. (6) in Ludwig (1977), i.e.:
where n is the number of nuclides in the part of the decay chain under consideration (this includes 206Pb, for which λ=0, but excludes any preceding nuclides for h and p). Similarly, for the 235U decay chain, we have
where and
where d is the Bateman coefficient defined in an equivalent manner to above. Identical equations may also be derived via the matrix exponential approach (e.g. Albarède, 1995), or using the Laplace transformation (Catchen, 1984). However, we have opted to preserve the original Bateman form for the purpose of clarity and because we see no advantage in adopting these alternative forms here. These disequilibrium U–Pb equations may be employed to compute ages using single aliquot or diagrammatic approaches in a similar fashion to the more familiar U–Pb equations, although they require numerical methods to solve in all instances (see discussion below).
When dealing with materials young enough to retain [] or [] values that are analytically resolvable from radioactive equilibrium, it is generally more accurate to use present-day (i.e. measured) activity ratios rather than assumed initial values. This information can be incorporated into the above equations by employing an “inverted” form of the U-series age equations, whereby initial activity ratios are expressed as a function of present-day ratios and t (Woodhead et al., 2006). These equations may then be substituted into the disequilibrium U–Pb equations above and included in the numerical solving procedure, resulting in a solution to both age and the initial activity ratio value. For example, this approach has been widely applied to Quaternary speleothems using measured [] values (e.g. Woodhead et al., 2006; Pickering et al., 2011; Bajo et al., 2012).
3.1 and 207Pb-corrected ages
The most straightforward implementation of the disequilibrium U–Pb age equations outlined above involves treating each U decay series independently to compute a radiogenic or age. This is achieved by solving
or
where the subscript meas. denotes a measured ratio corrected for blank and common Pb, and F and G are given above (Eqs. 1–5, and 7–9). This age-calculation approach may be applied, for example, to compute ages in young, radiogenic Pb-rich minerals such as Quaternary zircons, provided that common Pb is negligible or can be accurately corrected for (e.g. von Quadt et al., 2014).
Where common Pb is not negligible, or not amenable to accurate correction based on the measurement of 204Pb-based ratios (e.g. in samples analysed by ICP–MS techniques), a version of the 207Pb-corrected age employed by SIMS analysts (e.g. Williams, 1998), but modified to account for disequilibrium (Sakata, 2018), may be more practically useful. This approach, which is similar to the “single-aliquot” method of Woodhead et al. (2012) for calculating ages in high speleothems, involves plotting each data point, uncorrected for common Pb and disequilibrium, on a Tera–Wasserburg diagram ( vs. ; Tera and Wasserburg, 1972) and projecting a line from a common initial value on the y-axis intercept, through each data point to the disequilibrium concordia (Fig. 2). An intercept age may then be computed for each data point, assuming concordance between the 238U and 235U decay schemes (Chew et al., 2011). This provides a means of correcting ages for common Pb and disequilibrium in an internally consistent fashion. However, unlike the disequilibrium concordia intercept approach outlined below (Sect. 3.3), the common Pb composition is not given by linear regression of the data points themselves and must be specified independently. For igneous minerals, this may be achieved using whole rock measurements, analysis of Pb isotope ratios in co-genetic phases with high common ratios (e.g. K-feldspars) or model estimates of average crustal Pb composition, such as that of Stacey and Kramers (1975).
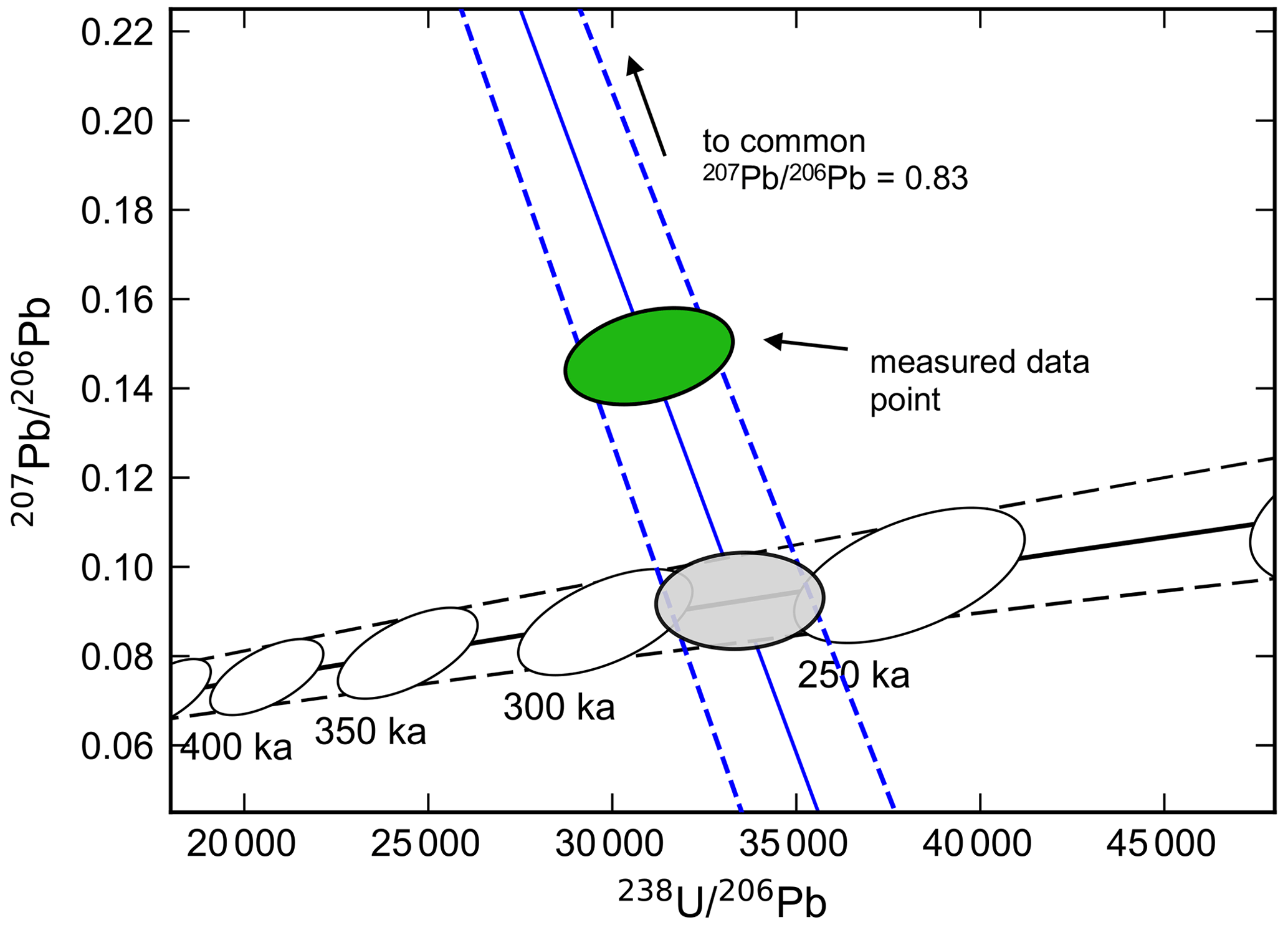
Figure 2Graphical representation of a 207Pb-corrected age calculation. A straight line (blue) is projected from the initial value at the y-axis intercept through the measured data point to the disequilibrium concordia curve, constructed here using = 0.2 ± 0.1 (2σ) and = 2.9 ± 0.8 (2σ). The dashed black lines represent uncertainties (95 % CI) in the trajectory of the concordia arising due to distribution coefficient uncertainties (see Sect. 6). Age markers along the disequilibrium concordia are shown as 95 % confidence ellipses (white), also accounting for distribution coefficient uncertainties. The 207Pb-corrected age of 275 ± 23 ka (95 % CI) is represented by the grey intercept ellipse (95 % confidence). Note that the equilibrium concordia, if plotted, would appear as a horizontal line along the bottom of this figure at y≈0.046.
To compute disequilibrium U–Pb ages using these approaches, it is necessary to specify the initial radioactive disequilibrium state of long-lived intermediate nuclides. For minerals that are assumed to have crystallised from a melt in secular equilibrium, may be computed according to the following relationship (e.g. McLean et al., 2011):
where min. denotes mineral and is the ratio of mineral–melt partition coefficients (i.e. ). An equivalent expression may be written for . Based on this relationship, it is possible to account for disequilibrium in computing U–Pb ages for co-genetic igneous minerals using one of two different approaches, each entailing different assumptions regarding mineral–melt partitioning.
Approach (i) assumes that the elemental ratio of the melt is constant, but may vary across different grains. For this approach, is estimated from whole rock measurements (Schärer, 1984), or measured in co-genetic phases assumed to be representative of the original melt composition (e.g. volcanic glasses, Rioux et al., 2012). values are then determined based on either direct measurement of in each mineral grain (e.g. in LA-ICP-MS analyses, Guillong et al., 2014), or inferred from the radiogenic ratio and age using an iterative procedure (e.g. in TIMS analyses, Crowley et al., 2007). Approach (ii), on the other hand, assumes that is constant for all mineral grains, implying that of the magma may be heterogenous. For this approach, values may be estimated based on experimental values or average values from geologically similar contexts (e.g. Sakata, 2018). For estimating values, the second approach is more widely applicable, owing to difficulties inherent in constraining values of the melt. It is also more easily justified for 207Pb-corrected ages owing to their lower sensitivity to this value (Sakata et al., 2017).
For a suite of co-genetic mineral grains that are thought to belong to a single statistical population, a weighted average age may be computed using
equivalent approaches to conventional U–Pb ages. However, in the case of disequilibrium ages, uncertainty in for
approach (i) outlined above, or and for approach (ii), acts as a systemic component of uncertainty, giving rise to
correlated age uncertainties. These correlations can be non-trivial and should be considered in any weighted average calculation to accurately
propagate assigned uncertainties and avoid artificially deflating mean squared weighted deviation (MSWD) statistic (McLean et al., 2011). DQPB allows
users to compute disequilibrium and 207Pb-corrected ages, specifying the initial disequilibrium state using either of the approaches above. For approach (i), either a measured or radiogenic ratio with analytical uncertainty is input for each aliquot along with a common value and uncertainty. For approach (ii), a common () value and uncertainty is input and applied to all aliquots under the assumption that these uncertainties are perfectly correlated. Age uncertainties and uncertainty covariances are then estimated by either Monte Carlo methods or analytical uncertainty propagation (see Sect. 5), and where appropriate, weighted average ages accounting for this covariance structure may be computed using
either classical or robust statistical approaches (see Sect. 4 for further details).
3.2 “Classical” U–Pb isochron ages
Disequilibrium 238U–206Pb and 235U–207Pb “classical” isochron ages may be computed for common Pb-rich samples by numerically solving or , where b is the slope of the isochron regression line on a vs. or vs. diagram, respectively. For classical U–Pb isochron diagrams, isotope ratios are traditionally referenced to 204Pb, however, when dating young materials with very low 232Th abundance, such as carbonates with low detrital content, it is also possible to reference to 208Pb instead under the assumption that 232Th has produced negligible radiogenic 208Pb since the time of system closure (Getty et al., 2001). The two formulations are mathematically equivalent, but the latter can be advantageous where accurate an measurement of 204Pb proves difficult, such as in ICP–MS dating of young samples (Engel et al., 2019). While U–Pb isochron approaches can be less reliable than concordia intercept ages (Ludwig, 1998), especially for young datasets incorporating the low abundance 204Pb isotope, they are offered in DQPB because of their potential utility in computing ages for Pb-rich materials where the disequilibrium state of only one of the U-series decay chains is well constrained.
3.3 Concordia intercept ages
Concordia intercept ages are well-suited to Pb-rich materials such as carbonates and apatite that typically contain variable Pb*/common Pb ratios within individual growth horizons (Woodhead and Pickering, 2012; Chew et al., 2011; Engel and Pickering, 2022). To compute ages using this approach, multiple co-genetic samples uncorrected for common Pb are plotted on a Tera–Wasserburg diagram. If all samples (i) have remained closed to the exchange of U-series isotopes post crystallisation, (ii) contain varying quantities of common Pb with an identical composition and (iii) were initially crystallised in the same disequilibrium state, they form a mixing line on a Tera–Wasserburg diagram between a purely radiogenic end-member lying on the concordia curve (the locus of all radiogenic Pb ICs through time) and a common Pb end-member at the y-axis intercept (Tera and Wasserburg, 1972). When accounting for the effects of radioactive disequilibrium, the familiar equilibrium concordia is replaced with a family of disequilibrium concordia constructs (e.g. Wendt and Carl, 1985), based on the following equations:
and
where U denotes the present-day natural ratio. Activity ratios may either be input directly into functions F and G as initial values, or as present-day values via the inverted U-series equations as described in Sect. 3, and ages are then calculated as the intersection of a regression line with the appropriate concordia curve, by solving
where a and b are the slope and y-intercept values obtained by linear regression of the data points. DQPB allows users to fit a variety
of regression models to Tera–Wasserburg data (Sect. 4), compute ages based on either initial or present-day (i.e. measured) intermediate nuclide
activity ratios values, and construct customisable plots of the disequilibrium concordia intercept ages (e.g. Fig. 3).
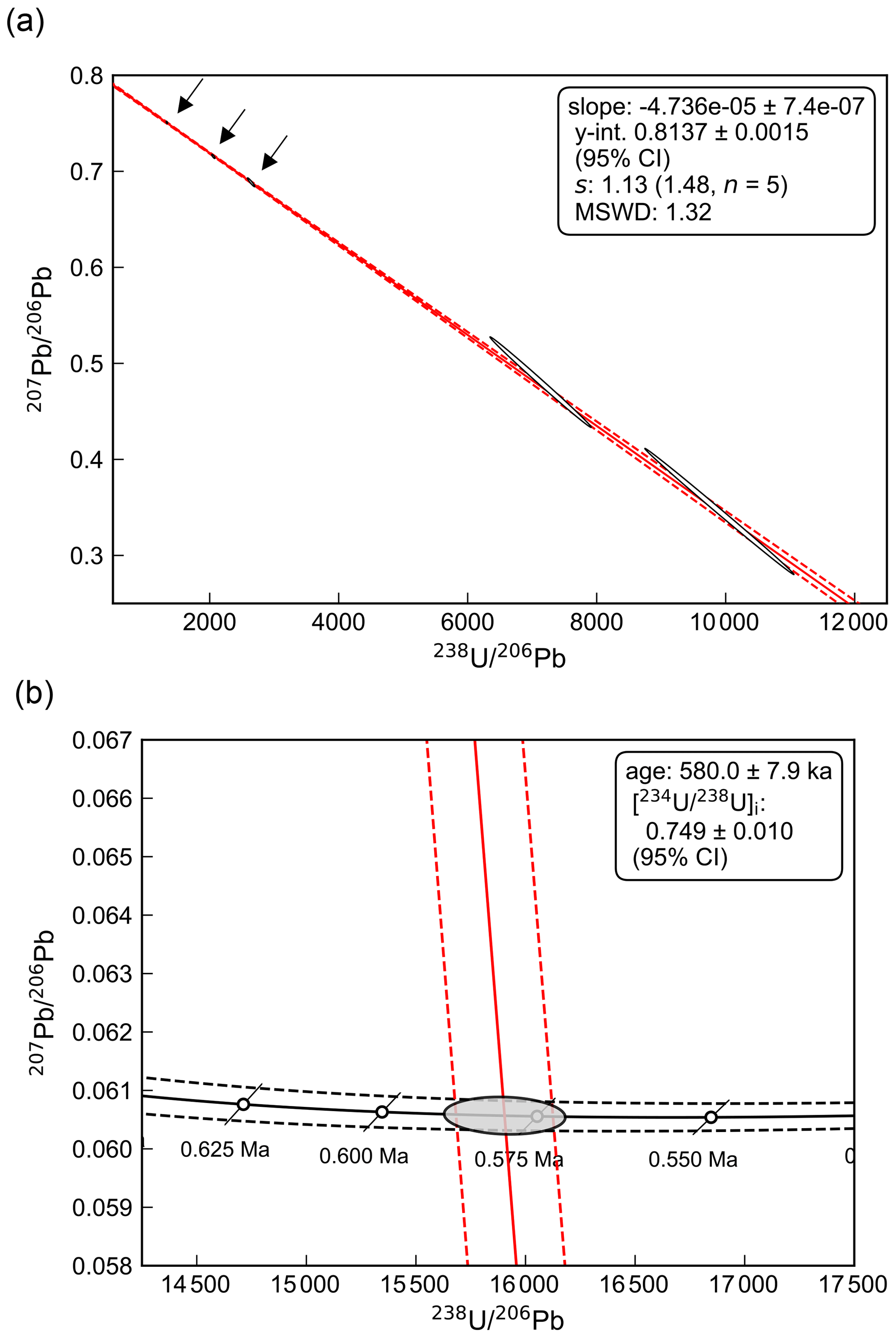
Figure 3Example of Tera–Wasserburg concordia intercept age plots for Middle Pleistocene stalagmite CCB (see Sect. 7.1 for further details). (a) Plot showing the spine linear regression fit to data (red line), with dashed red lines indicating uncertainties (95 % confidence). Measured data points (white 95 % confidence ellipses), exhibit a strong negative uncertainty correlation due the effects of blank subtraction (Woodhead et al., 2012). (b) Enlarged view of the concordia intercept. The disequilibrium concordia line (black) is constructed using a measured [] value of 0.9512 ± 0.0013 (2σ), with initial activity ratios for other intermediate nuclides assumed equal to 0. The dashed black lines indicate uncertainties (95 % confidence) arising from uncertainty in this measured [] value. Regular concordia age markers are shown as white circles, and the black diagonal lines
represent 95 % confidence age ellipses, which are collapsed to straight line segments because there is no uncertainty assigned to [] (see Sect. 6). The grey “intercept ellipse” (95 % confidence) is representative of the 106 simulated concordia intercept points from the Monte Carlo simulation.
3.4 “Forced concordance” initial [ ] values
DQPB also implements a version of the “forced concordance” routine of Engel et al. (2019), which targets closed-system samples where the
initial activity ratio is unknown, but activity ratios of other long-lived intermediate nuclides (i.e.
[] and []) are reliably constrained (e.g. very low initial Th carbonates). The routine
determines the [] value that forces concordance between the 235U–207Pb and 238U–206Pb
decay schemes based on individual U–Pb isochrons and outputs this value along with its uncertainty computed by Monte Carlo methods. This algorithm may be useful for characterising
initial [] values for particular geological contexts (e.g. cave sites when dating carbonate speleothems) where all available
samples lie beyond the range of measurable disequilibrium.
Linear regression and weighted average age algorithms capable of accounting for analytical uncertainties and accommodating the possibility of “excess
scatter” (i.e. scatter in excess of that which is attributable to assigned analytical uncertainties) are crucial for attaining reliable
U–Pb ages. DQPB offers two distinct approaches to perform linear regression and compute weighted averages. The first of
these (Sect. 4.1) is rooted in a classical statistical paradigm and emulates the default protocols of Isoplot (Ludwig, 2012). The second approach (Sect. 4.2) takes advantage of recent developments in the application of robust statistics to
geochronology, implementing the spine algorithm of Powell et al. (2020) as well a weighted average variant of this algorithm (the “spine” weighted average), and a newly developed robust regression algorithm (the “robust model 2”). Although users are free to choose the most appropriate algorithm for their particular dataset, the spine linear regression and weighted average algorithms are set as the default because they are considered suitable for a wider range of datasets than their classical statistics-based counterparts.
4.1 Classical statistical approaches
For the classical statistics-based approach, linear regression and weighted averaging of data are first performed using algorithms that weight data points according to assigned analytical uncertainties under the assumption that these are the only source of data point scatter. For linear regression, this involves implementing the error-weighted least-squares algorithm of York et al. (2004), which yields equivalent results to the original algorithm of York (1969) with uncertainties on regression parameters calculated following the maximum likelihood estimation (MLE) approach of Titterington and Halliday (1979). For weighted average calculations, an uncertainty-weighted least-squares algorithm is implemented whereby individual data points are weighted according to the inverse of their analytical variance, accounting for the uncertainty covariance structure where relevant (e.g. McLean et al., 2011). An apparent advantage of this classical approach is that it allows a statistic with a well-established distribution, i.e. the MSWD, to be used to assess data point scatter in relation to measurement uncertainties under the assumption that residuals are strictly Gaussian distributed (Wendt and Carl, 1985). Probabilistic-based conclusions can then be drawn regarding the likely presence (or not) of excess scatter.
Where the MSWD lies within a probabilistically acceptable range about 1, as indicated either by a confidence interval on MSWD (e.g. Powell et al., 2002) or, equivalently, the “probability-of-fit” value (Ludwig, 2012), the initial least-squares solution and analytical uncertainty-based standard errors are retained. However, if the MSWD value falls outside such limits, the dataset is deemed likely to contain a component of excess scatter, which may be either “geological scatter” (variability in initial Pb composition, open-system behaviour etc.) or some component of analytical uncertainty that is unaccounted for. Provided that the MSWD is not unreasonably high, assigned analytical uncertainties likely still dominate the uncertainty budget, and, on this basis, the initial least-squares solution is retained, but uncertainties are inflated so as to reduce the MSWD to 1. For linear regression fitting, this may be termed the “model 1x”, borrowing the terminology of Powell et al. (2020). On the other hand, where the MSWD lies well outside a probabilistically acceptable range, the assumptions of the York fit or analytical uncertainty-weighted average are clearly violated, and it is commonplace to either manually reject data points to restore scatter to an acceptable range or turn to alternative
classical statistics-based approaches, for example, by employing the Isoplot model 2 or model 3 fits (Ludwig, 2012).
Although this classical statistics-based approach is predominant within geochronology, it has some limitations. Firstly, the rejection of outliers from small sample sizes typical in geochronology is notoriously difficult. Secondly, this approach relies on a stepwise mode of uncertainty handling, which is both conceptually unsatisfying and requires the choice of arbitrary cut-off points, the values of which can have a substantial impact on calculated ages and uncertainties (see Powell et al., 2020). Thirdly, the MSWD statistic is very sensitive to small departures in residuals from a strict Gaussian distribution, making it an overly sensitive indicator of excess scatter for many real-world geochronological datasets, which are often slightly “heavy tailed” (Rock et al., 1987; Powell et al., 2002). And lastly, the model 2 and 3 linear regression algorithms are not well-suited to all datasets. For example, the model 3 fit parameterises excess scatter as an external Gaussian-distributed component of scatter, an assumption that is difficult to justify in the typical case where the precise cause of excess scatter is not well-established nor known to be strictly Gaussian (Ludwig, 2003). The model 2 fit, on the other hand, makes few assumptions regarding the statistical distribution of the excess scatter, however, it weights all data points equally and does not account for analytical uncertainties at all.
4.2 Robust statistical approaches
Robust algorithms, which do not rely on the assumption of Gaussian-distributed residuals, offer a means of addressing some of the limitations of the classical statistics-based approach outlined above. Robust statistical approaches have previously been proposed in geochronology, including the median-of-medians linear regression algorithm (Siegel, 1982), which is implemented in Isoplot (Ludwig, 2012) and weighted average algorithms
of varying complexity (e.g. Rock et al., 1987; Ludwig, 2012). While these algorithms are resistant to the effects of outliers, a limitation of these
approaches is that they ignore analytical uncertainties, leading to suboptimal results where these do in fact constitute a significant component of the total data point scatter. The spine linear regression algorithm (Powell et al., 2020) improves on these previous robust approaches by
accounting for assigned analytical uncertainties; it also exhibits a number of favourable properties that arguably make it more generally applicable to
geochronological datasets compared to the classical statistics-based approach.
The spine algorithm minimises a piece-wise objective function (the “Huber loss function”), whereby data points lying along a central linear
band (i.e. the spine) are given full weighting, but points falling outside this band are progressively down-weighted according to their weighted
residual. Uncertainties on regression parameters are calculated using a first-order error propagation approach and tend to increase smoothly with
increasing data point scatter. Notably, in the case where all data points lie within this central band, spine yields identical results to
York, making this algorithm suitable for both “well-behaved” and excess scatter datasets, provided that the majority of data points
comprise a well-defined linear array within their uncertainties. In the place of the MSWD, a robust statistic called the spine width, s, may be used to assess whether or not data point scatter is commensurate with accurate use of this algorithm given assigned uncertainties. The s statistic is the median absolute deviation of weighted residuals, normalised to be equal to the standard deviation for a strictly Gaussian distribution (i.e. NMAD). This statistic tends towards 1 for well-behaved datasets and may be employed in a similar manner to the MSWD, although, in contrast to MSWD, confidence intervals on s must be derived from simulation rather than from a formal statistical distribution (Powell et al., 2020). DQPB outputs s along with this
simulated upper 95 % confidence bound (here denoted slim) allowing users to assess if the central spine of data is sufficiently
well-defined for use of this regression algorithm.
For computing robust weighted averages, DQPB also offers a one-dimensional variant of the spine linear regression algorithm, termed the spine weighted average (see Appendix A). The spine weighted average is capable of accounting for assigned analytical uncertainties, and like the classical least-squares approach, it can accommodate uncertainty correlations among data points. Analogously to the linear regression version, it gives full analytical weighting to data at the centre of the distribution, and progressively down-weights data points lying away from this central spine according to the Huber loss function. In the case where data point scatter is commensurate with analytical
uncertainties, the spine weighted average reduces to the classical statistics weighted mean (e.g. Powell and Holland, 1988; McLean et al., 2011). Equivalently to the spine regression algorithm, the quality of this central spine of data points can be assessed by considering s in relation to slim which is derived via the simulation of Gaussian distributed datasets (see Appendix B).
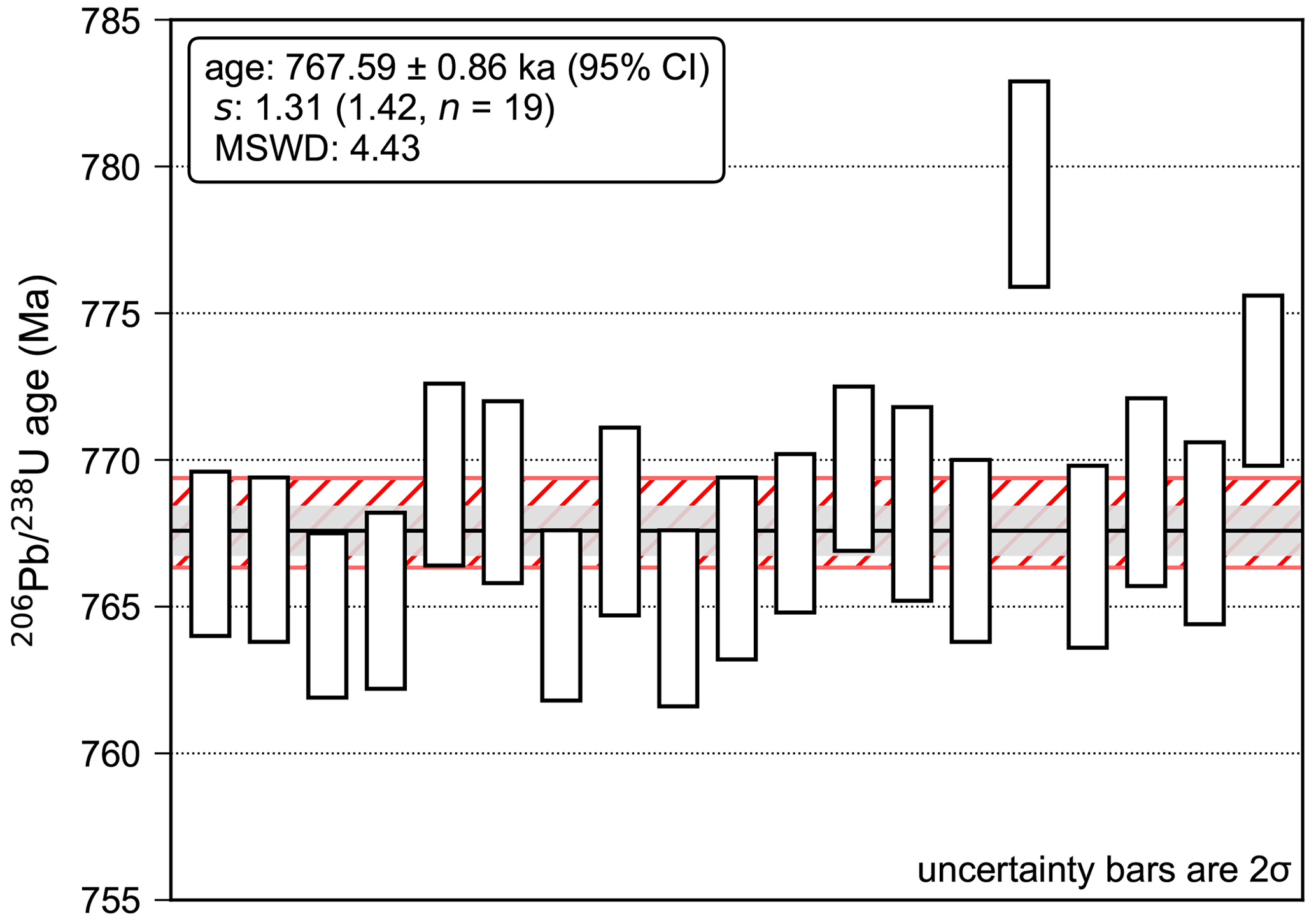
Figure 4A comparison of the spine weighted average with the classical statistics weighted mean for Bishop Tuff zircon ages from Crowley et al. (2007). The black line shows the spine weighted average age of 767.59 ± 0.86 ka (95 % CI), with this uncertainty indicated by the light grey shading. The spine width value, s, for this dataset is 1.31, which is within the upper 95 % confidence limit of s (slim = 1.42, n=19), suggesting that the dataset contains a sufficiently well-defined spine of data points for use of this algorithm. For comparison, the classical statistics weighted mean age is 767.85 ± 1.5 ka (95 % CI) (MSWD = 4.43, n=19), with this uncertainty represented by the hatched red area. If the two oldest ages are treated as outliers, as for the preferred age in the original publication, the classical statistics weighted mean shifts to 767.06 ± 0.85 ka (95 % CI) (MSWD = 1.3, n=17). Note that age uncertainty covariances have not been considered in this example, although the spine algorithm is capable of accounting for these where necessary (see Sect. 4).
In addition to the spine linear regression algorithm, DQPB also offers a second robust linear regression approach for datasets that
have an s value exceeding slim but are still reasonably thought to have age significance (see Appendix C). This regression algorithm,
named the “Robust model 2”, is similar to the Isoplot model 2, but encompasses robust properties which reduce the influence of outliers on
the fitted line in a similar manner to spine. Although this algorithm discards analytical uncertainties and provides less reliable age
uncertainty estimates than spine, it is offered as a robust alternative to the model 2 and 3 fits discussed above, as it is expected to be applicable to a wider range of datasets.
First-order analytical uncertainty propagation is a suitable method for computing U–Pb age uncertainties in cases where input variables (e.g. measurements, regression fit parameters and activity ratios) have relatively small uncertainties, and the age equation is linear with respect to these variables within the neighbourhood of the age solution (e.g. Barlow, 1989). However, this approach can be inaccurate where uncertainties on input variables are relatively large, and the linear approximation breaks down. For example, applying analytical uncertainty propagation to isochron or concordia intercept ages with large regression fitting uncertainties can result in inaccurate age uncertainties, because the age solution PDF (probability density function) can be markedly asymmetric.
Monte Carlo simulation is an alternative approach to propagating U–Pb age uncertainties, which is not reliant on a linear
approximation. With this approach, input variables are randomly sampled from within their PDFs (typical Gaussian or multivariate Gaussian
distributions) for each trial, and an age is calculated. This procedure is then repeated many times to build up an estimate of the output age PDF
from which summary statistics (e.g. standard deviation or confidence intervals) can be estimated. Monte Carlo simulation is capable of accounting for asymmetric age distributions and can provide accurate results even when uncertainties on input variables are large (e.g. Albarède, 1995). However, a potential drawback of the Monte Carlo approach is that, owing to its stochastic nature, it requires a large number of trials to produce numerically accurate and stable results, making it more computationally intensive than analytical approaches. The reliability of Monte Carlo uncertainty estimates scales with the number of trials. Although the number of trials required to produce 95 % confidence intervals that are accurate to about two significant digits depends on the shape of the output age PDF, 105–106 trials are
typically sufficient (e.g. JCGM, 2008). For most age calculations in DQPB, Monte Carlo uncertainty calculations involving
105–106 trials are completed in a matter of seconds, although, calculations can take longer in cases where either uncertainties on input variables are very large or there is a high proportion of trials with non-convergent age solutions. DQPB allows users to adjust the number of Monte Carlo trials. By default, this is set to 5 × 104 for
convenience, but it is recommended to increase this to ∼ 106 when computing final age uncertainties by Monte Carlo simulation.
5.1 Monte Carlo uncertainties
DQPB offers Monte Carlo uncertainty propagation for all disequilibrium U–Pb age types. For concordia intercept and
classical isochron datasets fitted either using robust or model 1 algorithms, regression parameters are randomised within uncertainties according
to a multivariate Gaussian distribution for each trial, accounting for uncertainty correlation between the slope and y-intercept. For model 1x,
model 2 and model 3 fits, (i.e. excess scatter fits) regression parameters are instead randomised within their “observed scatter”
uncertainties, i.e. 1σ analytical uncertainties multiplied by according to a bivariate t distribution with n−2
degrees of freedom, where n is the number of data points. Activity ratios, either as initial or present-day values, are then randomised according to
univariate Gaussian distribution, and an age is computed for each combination of inputs. In cases where a present-day activity ratio value is given,
the initial activity ratio value is also computed for each trial as part of the numerical solving procedure. Age uncertainties are reported as a
95 % confidence interval, estimated from the 2.5 and 97.5 percentiles of simulated ages.
The application of Monte Carlo uncertainty propagation to disequilibrium ages, computed using present-day activity ratio values that are not clearly resolvable from radioactive equilibrium (i.e. where the activity ratio PDF significantly overlaps the radioactive equilibrium value),
can produce unreliable results. This is because random samples drawn from the overlapping part of the measured activity ratio PDF tend to produce
non-convergent age solutions, and this may bias the output age distribution. To address this issue, DQPB performs two checks to verify that
the input data are suitable for Monte Carlo uncertainty propagation. The first check is performed prior to commencing the simulation and ensures that
the measured activity ratio values are analytically resolvable from equilibrium with 95 % confidence. Where this criterion is not met, a warning
is displayed to the user, and the Monte Carlo simulation does not proceed. The age is still reported, but the uncertainties are listed as
undefined. The second check, which is performed after a Monte Carlo simulation is completed, verifies that a minimum number of trials were successful
(the default value is set to 97.5 %). Where this second criterion is not met, the software displays a warning that Monte Carlo simulation results
may be unreliable and should not be used. This second warning may also be triggered if the PDF of an initial activity ratio significantly overlaps
negative values (e.g. if the value of an initial activity ratio is assigned a value close to zero with some uncertainty), which may also lead to
unreliable age uncertainty estimates.
For multiple co-genetic and 207Pb-corrected ages, an approach similar to Renne et al. (2010) is used to account for systematic components of uncertainty. With this approach, isotope ratios for each data point are first randomised within their individual analytical uncertainties according to a Gaussian distribution (or a multivariate Gaussian distribution for 207Pb-corrected ages). Variables that contribute a systematic component of uncertainty, such as distribution coefficient or ratios (and initial values for 207Pb-corrected ages) are then randomised within their uncertainties once per trial, and this common value is used to compute an age for each data point. This procedure results in an m-by-n array of simulated ages (where m is the number of Monte Carlo trials and n is the number of single-aliquot ages) displaying the covariance resulting from their common dependence on these variables (e.g. Renne et al., 2010). Age uncertainties on individual aliquots are reported as 95 % confidence intervals and age covariances are estimated from simulated ages for each of the n data points, resulting in an n-by-n age covariance matrix. Where appropriate, this covariance structure is then used in subsequent weighted average age calculations.
5.2 Analytical uncertainty propagation
In addition to Monte Carlo uncertainty propagation, DQPB offers first-order analytical uncertainty propagation for and
207Pb-corrected ages. While Monte Carlo methods can provide more accurate age uncertainties for these age types when uncertainties on input
variables are large and result in asymmetric age distributions (as discussed above), such asymmetries are not typically accounted for in computing
weighted averages. Although it is possible in principle to account for the effects of asymmetries in weighted averages, such approaches are not yet
well developed in geochronology. At the same time, the computation time required to implement Monte Carlo uncertainty propagation for large n
(number of aliquots) and large m (number of trials) can be much more significant than for diagrammatic ages. For these reasons, analytical
uncertainty propagation may be preferable for these age types, provided that uncertainties on input variables are relatively small, and/or age uncertainties on all data points are known to be approximately Gaussian. DQPB implements a matrix-based approach for analytical uncertainty propagation that accounts for the effect of random and systematic components of uncertainty on each aliquot and keeps track of all covariance terms
(e.g. McLean et al., 2011). This approach allows the age covariance structure to be easily computed and used in subsequent weighted average age
calculations in an equivalent manner to the Monte Carlo approach discussed above.
DQPB outputs customisable plots for all diagrammatic and weighted average U–Pb age calculations. For isochron and concordia
ages, a plot of the linear regression fit is provided, showing data points as 95 % confidence ellipses along with the regression line and a
95 % confidence band on the regression fit. This confidence band is plotted using the approach of Ludwig (1980) for model 1, 2 and 3 fits and Monte
Carlo simulation for robust fits (e.g. Fig. 3a). For concordia intercept ages, an additional plot is also provided, showing an enlarged view of the
intersection between the regression line and the disequilibrium concordia curve (e.g. Fig. 3b). The intercept points of all Monte Carlo simulated ages are
also shown on this plot, either as m by x–y points or plotted as a single 95 % confidence ellipse representing the set of all simulated intercept points. For 207Pb-corrected ages, data points are plotted on a Tera–Wasserburg diagram. If and
are input as constant values for all data points, a disequilibrium concordia curve may also be plotted along with projection lines
from the common Pb point through each data point to its concordia intercept (e.g. Fig. 5a).
For disequilibrium concordia curves on concordia intercept plots, age markers may be plotted as either point markers or “age ellipses” that
represent uncertainty in x–y for a given t value arising from uncertainty in activity ratio values. Where there is uncertainty in activity
ratios for both the 238U and 235U decay series, these age ellipse markers are true ellipses, akin to those representing decay
constant uncertainties on an equilibrium Tera–Wasserburg concordia diagram (Ludwig, 1998). On the other hand, where there is activity ratio
uncertainty assigned to only one of the U decay schemes, these age ellipses collapse to line segments with a slope equivalent to the
Tera–Wasserburg isochron lines described in Eq. (7) of (Wendt and Carl, 1985). A 95 % confidence band representing uncertainty in the trajectory of the concordia curve arising from uncertainty in activity ratios may also be plotted, based on a Monte Carlo simulation. DQPB allows users to customise a wide range of plot settings, export figures in a variety of image file formats and access all numeric data used to construct plots via output to a new Excel spreadsheet (see Supplement for further details).
DQPB usage examples 7.1 Concordia intercept speleothem age
Despite their relatively low U content, clean (i.e. with low detrital content) carbonates, such as speleothems, can be well-suited to
U–Pb dating provided they contain relatively high ratios and spread in ratios within individual growth layers (Woodhead et al., 2012). Here, we demonstrate computation of a concordia intercept age for a Middle Pleistocene speleothem CCB from Corchia Cave,
Italy, based on solution MC-ICP-MS analyses. The sample is young enough to retain a [] ratio which is analytically resolvable from equilibrium but lies just beyond reach of the 230Th geochronometer using routine methods. A measured activity ratio of 0.9512 ± 0.0013 (2σ) was used in the age calculation, obtained via MC-ICP-MS (Hellstrom, 2003). Speleothems from this cave site consistently exhibit very low detrital Th (as reflected in ratios; Drysdale et al., 2012) and
thus the initial [] is assumed equal to 0. The initial activity ratios for other intermediate nuclides are likewise assumed
equal to 0. The data are regressed using the spine algorithm, which in this case returns equivalent results to the York algorithm
(Fig. 3a). A lower intercept age of 580 ± 7.9 ka (95 % CI) is computed, along with an initial
[] value of 0.749 ± 0.010 (95 % CI). Age uncertainties are estimated by Monte Carlo simulation using 106 trials
(Fig. 3b).
7.2 Quaternary zircon 207Pb-corrected ages
In this example, we demonstrate a 207Pb-corrected age calculation for a suite of zircons from the Sambe–Kisuki tephra (Shuhei Sakata, unpublished data), which is thought to have erupted approximately 100 ka ago from the Sambe volcano located in the Shimane prefecture in the west of Japan. Analyses were performed by multi-collector LA-ICP-MS using a method similar to Hattori et al. (2017). Disequilibrium ages were calculated following approach (i) outlined in Sect. 3.1 using a value of 0.2 ± 0.06 (2σ), a value of 3.4 ± 0.8 (2σ) and a common value based on the two-stage model of Stacey and Kramers (1975). With this approach, uncertainties in and are propagated as purely systematic components of uncertainty. Age uncertainties were calculated by the Monte Carlo simulation, using 106 trials for each age point (Fig. 5a). These uncertainties are identical (within the quoted number of significant figures) to those obtained by analytical uncertainty propagation.
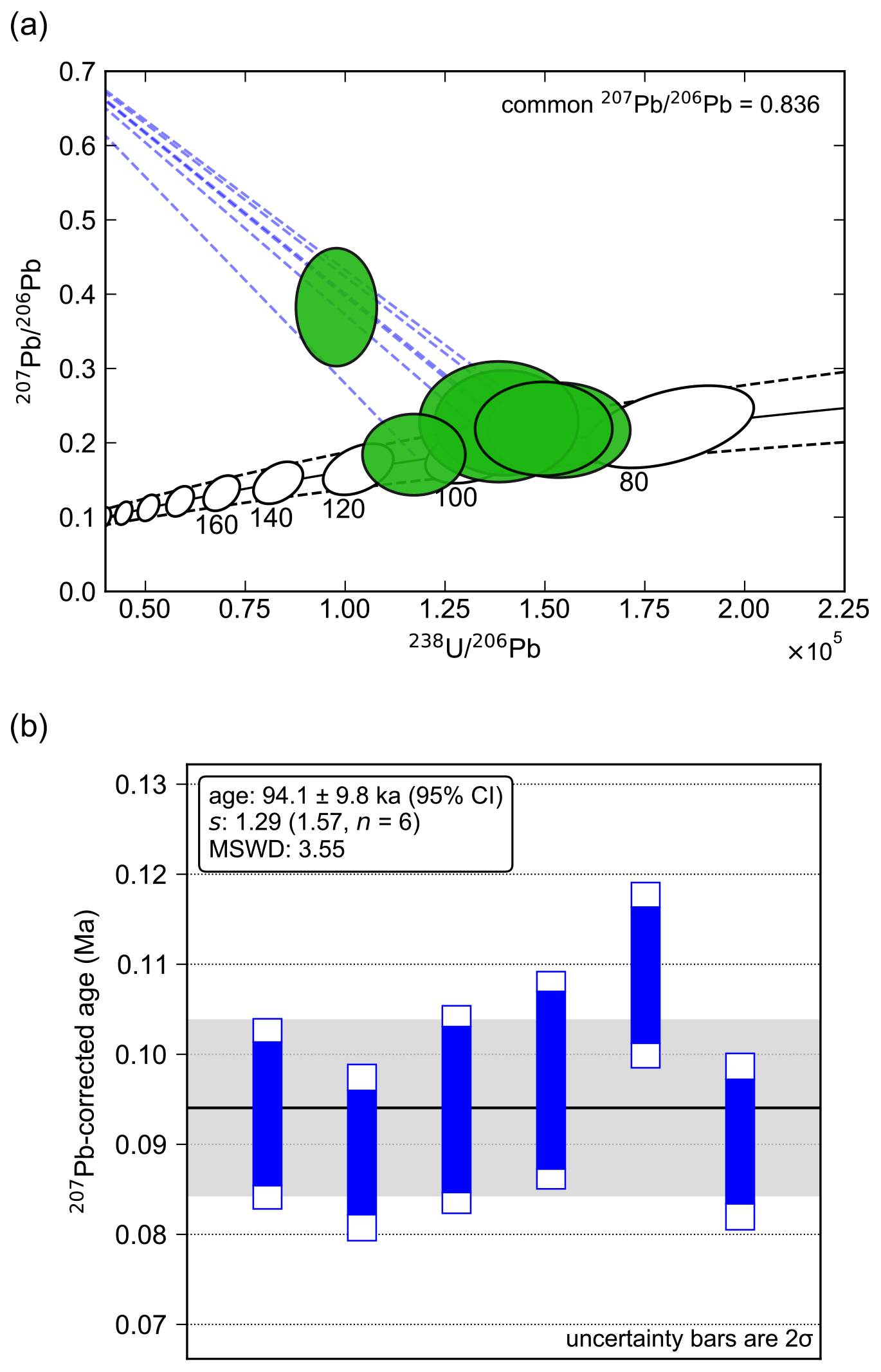
Figure 5Example of 207Pb-corrected age plots. (a) Data ellipses plotted on a Tera–Wasserburg diagram as 95 % confidence ellipses (green). The black line shows the disequilibrium concordia constructed using = 0.2 ± 0.06 (2σ) and = 3.4 ± 0.8 (2σ), with dashed black lines indicating uncertainty bounds (95 % CI). Concordia markers are plotted as 95 % age ellipses, representing x–y uncertainty for a given age due to uncertainty in distribution coefficients. The dashed blue lines show a line projecting from the common Pb point at the y intercept ( = 0.836) through the centre of each data point to its intercept with the disequilibrium concordia. (b) Plot of individual 207Pb-corrected ages. The dark blue bars indicate age uncertainties (2σ) accounting for random analytical uncertainties only, while the larger white bars show combined random and systematic uncertainties (2σ) (i.e. including components due to uncertainty in and values). The black line shows the weighted average age computed using the robust spine algorithm accounting for the age covariance structure, with the light grey shading indicating a 95 % confidence interval on this weighted average. Initial disequilibrium corrections were applied assuming constant distribution coefficient ratios, i.e. approach (i) in Sect. 3.1, treating uncertainties in and as purely systematic uncertainties.
Computing a weighted average using a classical statistics-based approach (accounting for uncertainty correlations), gives a weighted mean age of
95.0 ± 19 ka (95 % CI), with an MSWD of 3.55, indicating a very high probability of excess scatter in the dataset under the
assumption of Gaussian-distributed residuals. On the other hand, the robust spine weighted average algorithm gives a weighted average age of
94.1 ± 9.8 ka (95 % CI) (Fig. 5b), with a s value of 1.29 which lies within the upper 95 % confidence
limit of s (slim=1.57, n=6). This suggests that there is a sufficiently well-defined spine of data at the centre of the distribution
for use of this algorithm, and thus the weighted average is likely to carry age significance under the assumption that crystallisation of these
zircons constitutes a geologically discrete event (e.g. see Ickert et al., 2015). Note that the spine weighted average algorithm down-weights the single point lying away from the average age line, and thus it has little influence on the computed weighted average. For comparison, excluding this point gives a classical weighted average age of 92.0 ± 7.8 ka (95 % CI) with an MSWD of 0.55.
DQPB (Pollard, 2023a) is released under a MIT license, permitting modification of the source code and re-distribution with minimal restrictions. The source
code may be viewed via an online code repository (see: https://github.com/timpol/DQPB, last access: 6 April 2023). This
repository also contains links to downloadable installers for macOS and Windows, as well as online documentation. Suggestions for bug fixes and new features,
as well as pull requests, are also accepted via this repository.
In addition to the stand-alone GUI version of the software, DQPB is also available as part of a pure Python package named pysoplot (Pollard, 2023b),
offering greater flexibility for more experienced Python users. The pysoplot package is hosted at a separate online repository (see:
https://github.com/timpol/pysoplot, last access: 6 April 2023) and is available via pip (the package installer for Python) –
see: https://pypi.org/project/pysoplot/ (last access: 6 April 2023).
This paper introduces DQPB, an open-source software package for calculating disequilibrium U–Pb ages. The software implements
disequilibrium U–Pb equations to compute ages using various approaches, including disequilibrium ages based on single
aliquots, U–Pb isochron ages and concordia intercept ages on a Tera–Wasserburg diagram. Various linear regression and weighted average
age algorithms are implemented in the software, including those based on both classical and robust statistics, and high-quality “publication-ready”
figures are output. A key feature of the stand-alone GUI-based version of the software is that it allows close integration with Microsoft Excel and
thus continues the legacy of Isoplot in allowing straightforward interaction with U–Pb datasets from within a simple
spreadsheet environment. DQPB is free open-source software, and all source-code is available for viewing and download via an online
repository. For more experienced Python users, DQPB is available as part of a pure Python package, which may be downloaded and modified with
minimal restrictions to meet individual requirements. This software will continue to be developed under an open-source model and new features will be
added in the future.
spine robust weighted average Following the logic of Powell et al. (2020) for the two-dimensional case, a robust weighted average accounting for analytical uncertainties may be obtained for one-dimensional data (e.g. multiple coeval ages). To achieve this in the general case where correlated age uncertainties are permitted, it is first necessary to express weighted residuals in an uncorrelated form. In the classical statistics-based solution (e.g. Powell and Holland, 1988; McLean et al., 2011), the weighted average age is obtained by finding that minimises the sum of squared weighted residuals:
where t is a column vector of ages, 1 is a column vector of ones, and Vt is the uncertainty (covariance) matrix of the ages. To apply the Huber loss function, which is defined as
where rk is the weighted residual of the kth data point and h=1.4, the sum of weighted residuals must first be recast as a sum of uncorrelated weighted residuals. This may be achieved via eigendecomposition of the covariance matrix:
where Λ is the eigenvalue matrix consisting of positive eigenvalues on the diagonals and Q is the eigenvector matrix. From this we obtain
which can be substituted into Eq. (A1) to give
where r is a column vector of weighted residuals, given by
Following the approach in Powell et al. (2020), we minimise ∑ρk by finding the value that solves
where
This is achieved using an iterative reweighting procedure, whereby the weight function is introduced, resulting in
with
and
such that Wh is a diagonal matrix having w(rk) as the kkth element. This combines the weighting from w with the weighting from the correlated uncertainties on t. Rearranging this gives an expression equivalent to Eq. (B13) in Powell et al. (2020):
which can be solved by iteration from a robust starting point (e.g. Maronna, 2019). Analogous to the development of Eq. (B17) in Powell et al. (2020), uncertainties on are then computed by first-order uncertainty propagation as
where .
In the case where all , then ψ(r)=r, and , so
and
yielding the classical statistics-based result.
spine weighted average s simulations To assess whether the central spine of data points is sufficiently well-defined to obtain a meaningful weighted average, we compare the spine width, s, to its upper 95 % confidence limit bound derived via simulation of Gaussian-distributed datasets. Simulations were performed using sample sizes, n, ranging between 5–100 data points. For each n, 106 pseudorandom samples were drawn from a standard normal distribution; s values were computed for each sample, and confidence limits on s were estimated based on relevant percentiles (see Table B1). Odd and even n are considered independently in order to account for the effect of small sample bias inherent to NMAD (e.g. Hayes et al., 2014). The impact of different uncertainty covariance structures on s were also examined and found to have a negligible effect on these confidence limits.
Table B1Simulated 95 % confidence intervals for and s (spine width) as a function of the number of data points, n, where ∗ denotes a one-sided upper 95 % confidence limit. The results for MSWD are equivalent to those obtained from formal statistical tables. DQPB outputs the one-sided upper 95 % confidence limit on s (denoted slim in the software) to evaluate suitability of the spine weighted average algorithm for a particular dataset. DQPB also outputs equivalent values for the spine linear regression which are given in Table 1 of Powell et al. (2020).

The robust data-fitting algorithm in Powell et al. (2020) in the two-dimensional case, and above in Appendix A, in the one-dimensional case, are predicated on the one-sided confidence intervals on the spine width (in Table 1, last column of Powell et al., 2020), and in Table B1 here). The calculation of age, and particularly the uncertainty on age, is appropriate for the case where a dataset gives a spine width that is consistent with the confidence interval.
Not covered is how best to proceed if in fact a dataset is not consistent with the confidence interval. Whereas the argument developed in Powell et al. (2020), and by extension here, is that datasets which are consistent with this interval are likely to have age significance, this becomes progressively more awkward to argue as the spine width increases. The view taken in this section is that the calculations advocated are for datasets that are considered to have age significance, commonly by geological inference, even though the spine width is outside the confidence interval.
Once the spine width is too large, the data-fitting should plausibly not depend on the analytical uncertainties on the data as these are deemed insufficient to account for the observed scatter. A clear-cut and robust way to proceed is then to discard the analytical uncertainties and rely on the scatter of the data – specifically the spine width – to provide the data uncertainties.
Model 2 in Isoplot provides a framework for how to proceed. As outlined in the Appendix of Powell et al. (2020), for the Isoplot
model 2, in which analytical uncertainties are discarded, data are fit y on x, and x on y, and the results combined, circumventing the
potentially deleterious effects of error-in-variables effects (e.g. Fuller, 1987). In Isoplot, such calculations are done by applying
ordinary least squares in the two calculations, giving the slopes, byx and , respectively, with the combined slope being given by
and
(see Powell et al., 2020, for notation and details).
In the equivalent of model 2 using the spine algorithm, the analytical uncertainties are discarded, then the spine width is calculated from the scatter of the data about the line, s=𝚗𝚖𝚊𝚍(e). The development in Appendix B of Powell et al. (2020) can be applied as is to the two
calculations required: y on x and x on y, except that the two definitions need to be changed: Eq. (B5)2 should involve We with diagonal elements, , and Eq. (B13) should involve W
with diagonal elements, .
Applying the spine algorithm in the above-modified form to fitting y on x and x on y allows the slope and the intercept a to be calculated, as in Appendix A3 of Powell et al. (2020). The covariance matrix for each slope and intercept can be calculated by Eq. (B17). Combination into a covariance matrix for {a,b} requires the observation that byx and bxy are uncorrelated. An error propagation is then straightforward to b, and in fact a good approximation is generally given by adding the constituent covariance matrices and dividing by 4.
The DQPB source code and compiled versions of the GUI application may be obtained from the repositories described in Sect. 8.
The example datasets discussed in Sect. 7 are included in the Supplement.
The supplement related to this article is available online at: https://doi.org/10.5194/gchron-5-181-2023-supplement.
JW and JH devised the initial concept with input from JE and TP. TP devised the computational approaches and wrote the software with assistance from JE and JH. RP and TP devised the spine weighted average approach. RP devised the robust model 2 approach and wrote the code for it. TP wrote the paper with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Shuhei Sakata kindly provided the unpublished Sambe-Kisuki zircon data. We thank reviewers Pieter Vermeesch and Ryan Ickert, as well as the editor Noah M. McLean, for their carefully considered comments and suggestions that have greatly improved the paper.
This research was supported by Australian Research Council grants DP110102185 (to Russell Drysdale, Jon Woodhead and John Hellstrom), DP160102969 (to Russell Drysdale and Jon Woodhead) and FL160100028 (to Jon Woodhead).
This paper was edited by Noah M. McLean and reviewed by Ryan Ickert and Pieter Vermeesch.
Albarède, F. (Ed.): Introduction to Geochemical Modelling, Cambridge University Press, Cambridge, https://doi.org/10.1017/CBO9780511622960, 1995. a, b
Bajo, P., Drysdale, R., Woodhead, J., Hellstrom, J., and Zanchetta, G.: High-resolution U-Pb dating of an early Pleistocene stalagmite from Corchia Cave (Central Italy), Quat. Geochronol., 14, 5–17, https://doi.org/10.1016/j.quageo.2012.10.005, 2012. a
Barlow, R. J.: A Guide to the Use of Statistical Methods in the Physical Sciences, in: The Manchester physics series, edited by: Sandiford, D. J., Mandl, F., and Phillips, A. C., John Wiley and Sons, Chichester, England, ISBN 0471922943, 1989. a
Bateman, H.: Solution of a system of differential equations occurring in the theory of radioactive transformations, P. Cam. Philos. Soc., 15, 423–427, 1910. a, b, c
Catchen, G.: Application of the equations of radioactive growth and decay to geochronological models and explicit solution of the equations by Laplace transformation, Isot. Geosci., 2, 181–195, 1984. a
Chew, D. M., Sylvester, P. J., and Tubrett, M. N.: U–Pb and Th–Pb Dating of apatite by LA-ICPMS, Chem. Geol., 280, 200–216, https://doi.org/10.1016/j.chemgeo.2010.11.010, 2011. a, b
Crowley, J. L., Schoene, B., Bowring, S. A.: U-Pb dating of zircon in the Bishop Tuff at the millennial scale, Geology, 35, 1123–1126, https://doi.org/10.1130/G24017A.1, 2007. a, b
Drysdale, R. N., Paul, B. T., Hellstrom, J. C., Couchoud, I., Greig, A., Bajo, P., Zanchetta, G., Isola, I., Spötl, C., Baneschi, I., Regattieri, E., and Woodhead, J. D.: Precise microsampling of poorly laminated speleothems for U-series dating, Quat. Geochronol., 14, 38–47, https://doi.org/10.1016/j.quageo.2012.06.009, 2012. a
Engel, J. and Pickering, R.: The role of inherited Pb in controlling the quality of speleothem U-Pb ages, Quat. Geochronol., 67, 101243, https://doi.org/10.1016/j.quageo.2021.101243, 2022. a
Engel, J., Woodhead, J., Hellstrom, J., Maas, R., Drysdale, R., and Ford, D.: Corrections for initial isotopic disequilibrium in the speleothem U-Pb dating method, Quat. Geochronol., 54, 101009, https://doi.org/10.1016/j.quageo.2019.101009, 2019. a, b, c
Engel, J., Maas, R., Woodhead, J., Tympel, J., and Greig, A.: A single-Column extraction chemistry for isotope dilution U-Pb dating of carbonate, Chem. Geol., 531, 119311, https://doi.org/10.1016/j.chemgeo.2019.119311, 2020. a
Fuller, W. R.: Measurement error models, John Wiley and Sons, 440 pp., https://doi.org/10.1002/9780470316665, 1987. a
Getty, S. R. and DePaolo, D. J.: Quaternary geochronology using the U-Th-Pb method, Geochim. Cosmochim. Ac., 59, 3267–3272, https://doi.org/10.1016/0016-7037(95)00197-8, 1995. a, b
Getty, S. R., Asmerom, Y., Quinn, T. M., and Budd, A. F.: Accelerated Pleistocene coral extinctions in the Caribbean Basin shown by uranium-lead (U-Pb) dating, Geology, 29, 639–642, https://doi.org/10.1130/0091-7613(2001)029<0639:APCEIT>2.0.CO;2, 2001. a
Guillong, M., von Quadt, A., Sakata, S., Peytcheva, I., and Bachmann, O.: LA-ICP-MS Pb-U Dating of young zircons from the Kos–Nisyros volcanic centre, SE Aegean Arc, J. Anal. Atom. Spectrom., 29, 963–970, https://doi.org/10.1039/C4JA00009A, 2014. a, b
Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., del Río, J. F., Wiebe, M., Peterson, P., Gérard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., and Oliphant, T. E.: Array programming with NumPy, Nature, 585, 357–362, 2020. a
Hattori, K., Sakata, S., Tanaka, M., Orihashi, Y., and Hirata, T.: U-Pb age determination for zircons using laser ablation-ICP-mass spectrometry equipped with six multiple-ion counting detectors, J. Anal. Atom. Spectrom., 32, 88–95, https://doi.org/10.1039/C6JA00311G, 2017. a
Hayes, K.: Finite-sample bias-correction factors for the median absolute deviation, Commun. Stat. Simulat., 43, 2205–2212, https://doi.org/10.1080/03610918.2012.748913, 2014. a
Hellstrom, J. C.: Rapid and accurate dating using parallel ion-counting multi-collector ICP-MS, J. Anal. Atom. Spectrom., 18, 1346, https://doi.org/10.1039/b308781f, 2003. a
Hunter, J. D.: Matplotlib: A 2D-graphics environment, Comput. Sci. Eng., 9, 90–95, https://doi.org/10.1109/MCSE.2007.55, 2007. a
Ickert, R. B., Mundil, R., Magee, C. W., and Mulcahy, S. R.: The U–Th–Pb systematics of zircon from the Bishop Tuff: A case study in challenges to high-precision geochronology at the millennial scale, Geochim. Cosmochim. Ac., 168, 88–110, https://doi.org/10.1016/j.gca.2015.07.018, 2015. a
Ivanovich, M. and Harmon, R. S.: Uranium-Series Disequilibrium: Applications to Earth, Marine, and Environmental Sciences, 2nd Edn., Clarendon Press, United Kingdom, ISBN 019854278X, 1992. a
Joint Committee for Guides in Metrology (JCGM): Evaluation of measurement data–Supplement 1 to the 'Guide to the expression of uncertainty in measurement' Propagation of Distributions Using a Monte Carlo Method, International Bureau of Weights and Measures (BIPM), Sèvres, France, 2008. a
Ludwig, K. R.: Effect of initial radioactive-daughter disequilibrium on U-Pb isotope apparent ages of young minerals, J. Res. US Geol. Surv., 5, 663–667, 1977. a, b, c, d, e
Ludwig, K. R.: Calculation of uncertainties of U-Pb isotope data, Earth Planet. Sc. Lett., 46, 212–220, 1980. a
Ludwig, K. R.: On the treatment of concordant uranium-lead ages, Geochim. Cosmochim. Ac., 62, 665–676, https://doi.org/10.1016/S0016-7037(98)00059-3, 1998. a, b
Ludwig, K. R.: Mathematical–statistical treatment of data and errors for Geochronology, in: Uranium-series geochemistry, Reviews in Mineralogy and Geochemistry, Vol. 52, edited by: Bourdon, B., Turner, S., Henderson, G. M., and Lundstrom, C. C., Mineralogical Society of America, Washington, D.C., USA, 631–656, ISBN 0939950545, 2003. a
Ludwig, K. R.: Isoplot/Ex Version 3.75: A Geochronological Toolkit for Microsoft Excel, Special Publication 4, Berkeley Geochronology Center, 2012. a, b, c, d, e, f, g
Maronna, R. A., Martin, D., Yohai, V. J., and Salibián-Barrera, M.: Robust statistics: Theory and Methods (with R), 2nd Edn., Hoboken, New Jersey, USA, ISBN 9781119214687, 2019. a
Mattinson, J. M.: Anomalous isotopic composition of lead in young zircons, in: Carnegie Institution Washington Yearbook 72, Carnegie Institution of Washington, 613–616, 1973. a
McLean, N. M., Bowring, J. F., and Bowring, S. A.: An algorithm for U-Pb isotope dilution data reduction and uncertainty propagation, Geochem. Geophy. Geosy., 12, Q0AA18, https://doi.org/10.1029/2010GC003478, 2011. a, b, c, d, e, f
Neymark, L. A., Amelin, Y. V., and Paces, J. B.: 206Pb-230Th-234U-238U and 207Pb-235U geochronology of Quaternary opal, Yucca Mountain, Nevada, Geochim. Cosmochim. Ac., 64, 2913–2928, https://doi.org/10.1016/S0016-7037(00)00408-7, 2000. a
Oliphant, T. E.: Python for scientific computing, Comput. Sci. Eng., 9, 10–20, https://doi.org/10.1109/MCSE.2007.58, 2007. a
Osmond, J. K. and Cowart, J. B.: Groundwater, in: Uranium-Series Disequilibrium and Applications to Environmental Problems, 2nd Edn., edited by: Ivanovich, M. and Harmon, R. S., Oxford Science Publications, Oxford, ISBN 019854278X, 1992. a
Paquette, J. L., Médard, E., Francomme, J., Bachèlery, P., and Hénot, J.-M.: LA-ICP-MS zircon timescale constraints of the Pleistocene latest magmatic activity in the Sancy Stratovolcano (French Massif Central), J. Volcanol. Geoth. Rese., 374, 52–61, https://doi.org/10.1016/j.jvolgeores.2019.02.015, 2019. a
Parrish, R. R.: U-Pb dating of monazite and its application to geological problems, Can. J. Earth Sci., 27, 1431–1450, 1990. a
Pickering, R., Dirks, P. H. G. M., Jinnah, Z., de Ruiter, D. J., Churchill, S. E., Herries, A. I. R., Woodhead, J. D., Hellstrom, J. C., and Berger, L. R.: Australopithecus sediba at 1.977 Ma and implications for the origins of the genus Homo, Science, 333, 1421–1423, https://doi.org/10.1126/science.1203697, 2011. a
Pollard, T. J.: DQPB, Zenodo [code], https://doi.org/10.5281/zenodo.7804190, 2023a. a
Pollard, T. J.: pysoplot, Zenodo [code], https://doi.org/10.5281/zenodo.7804162, 2023b. a
Powell, R. and Holland, T.: An internally consistent dataset with uncertainties and correlations: 3. Applications to geobarometry, worked examples and a computer program, J. Metamorph. Geol., 6, 173–204, https://doi.org/10.1111/j.1525-1314.1988.tb00415.x, 1988. a, b
Powell, R., Hergt, J., and Woodhead, J.: Improving isochron calculations with robust statistics and the bootstrap, Chem. Geol., 185, 191–204, 2002. a, b
Powell, R., Green, E. C. R., Marillo Sialer, E., and Woodhead, J.: Robust isochron calculation, Geochronology, 2, 325–342, https://doi.org/10.5194/gchron-2-325-2020, 2020. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r
Rasbury, E. T. and Cole, J. M.: Directly dating geologic events: U-Pb dating of carbonates, Rev. Geophys., 47, 261–27, https://doi.org/10.1029/2007RG000246, 2009. a
Renne, P. R., Mundil, R., Balco, G., Min, K., Ludwig, K. R.: Joint determination of 40K decay constants and for the Fish Canyon sanidine standard, and improved accuracy for geochronology. Geochim. Cosmochim. Ac., 74, 5349–5367, https://doi.org/10.1016/j.gca.2010.06.017, 2010. a, b
Richards, D. A., Bottrell, S. H., Cliff, R. A., Ströhle, K., and Rowe, P. J.: U-Pb Dating of a speleothem of Quaternary age, Geochim. Cosmochim. Ac., 62, 3683–3688, https://doi.org/10.1016/S0016-7037(98)00256-7, 1998. a, b
Rioux, M., Johan Lissenberg, C., McLean, N. M., Bowring, S. A., MacLeod, C. J., Hellebrand, E., and Shimizu, N.: Protracted Timescales of lower crustal growth at the fast-spreading East Pacific Rise, Nat. Geosci., 5, 275–278, https://doi.org/10.1038/ngeo1378, 2012. a
Rock, N. and Duffy, T.: REGRES: A FORTRAN-77 program to calculate nonparametric and “structural” parametric solutions to bivariate regression equations, Comput. Geosci., 12, 807–818, https://doi.org/10.1016/0098-3004(86)90031-2, 1986.
Rock, N., Webb, J., McNaughton, N., and Bell, G.: Nonparametric estimation of averages and errors for small data-sets in isotope geoscience: A proposal, Chemical Geology: Isotope Geoscience Section, 66, 163–177, https://doi.org/10.1016/0168-9622(87)90038-8, 1987. a, b
Sakata, S.: A practical method for calculating the U-Pb age of Quaternary zircon: Correction for common Pb and initial disequilibria, Geochem. J., 52, 281–286, https://doi.org/10.2343/geochemj.2.0508, 2018. a, b
Sakata, S., Hattori, K., and and, H. I. G.: Determination of U–Pb ages for young zircons using laser ablation-ICP-mass spectrometry coupled with an ion detection attenuator device, Wiley Online Library, https://doi.org/10.1111/j.1751-908X.2014.00320.x, 2014. a
Sakata, S., Hirakawa, S., Iwano, H., Danhara, T., Guillong, M., and Hirata, T.: A new approach for constraining the magnitude of initial disequilibrium in Quaternary zircons by coupled uranium and thorium decay series dating, Quat. Geochronol., 38, 1–12, https://doi.org/10.1016/j.quageo.2016.11.002, 2017. a
Schoene, B.: U–Th–Pb Geochronology, in: Treatise on Geochemistry, Vol. 4, edited by: Rudnick, R. L., 2nd Edn., Elsevier, 341–378, https://doi.org/10.1016/B978-0-08-095975-7.00310-7, 2014. a
Schärer, U.: The effect of initial 230Th disequilibrium on young U-Pb ages: The Makalu Case, Himalaya, Earth Planet. Sc. Lett., 67, 191–204, 1984. a, b, c, d
Schmitt, A. K.: Ion microprobe analysis of and an appraisal of protactinium partitioning in igneous zircon, Am. Mineral., 92, 691–694, 2007. a
Schmitz, M. D. and Schoene, B.: Derivation of isotope ratios, errors, and error correlations for U-Pb geochronology using 205Pb-235U-(233U)-spiked isotope dilution thermal ionization mass spectrometric data, Geochem. Geophy. Geosy., 8, 1–20, https://doi.org/10.1029/2006GC001492, 2007.
Siegel, A. F.: Robust regression Using repeated medians, Biometrika, 69, 242–244, 1982. a
Stacey, J. S. and Kramers, J. D.: Approximation of terrestrial lead isotope evolution by a two-stage model, Earth Planet. Sc. Lett., 26, 207–221, https://doi.org/10.1016/0012-821X(75)90088-6, 1975. a, b
Tera, F. and Wasserburg, G. J.: U-Th-Pb Systematics in lunar highland samples from the Luna 20 and Apollo 16 missions, Earth Planet. Sc. Lett., 17, 36–51, https://doi.org/10.1016/0012-821X(72)90257-9, 1972. a, b
Titterington, D. M. and Halliday, A. N.: On the fitting of parallel isochrons and the method of maximum likelihood, Chem. Geol., 26, 183–195, 1979. a
Vermeesch, P.: IsoplotR: A free and open toolbox for Geochronology, Geosci. Front., 9, 1479–1493, https://doi.org/10.1016/j.gsf.2018.04.001, 2018. a
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, I., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., and SciPy 1.0 Contributors: SciPy 1.0: Fundamental algorithms for scientific computing in Python, Nat. Methods, 17, 261–272, https://doi.org/10.1038/s41592-019-0686-2, 2020. a
von Quadt, A., Gallhofer, D., Guillong, M., Peytcheva, I., Waelle, M., and Sakata, S.: U–Pb dating of CA/non-CA treated zircons obtained by LA-ICP-MS and CA-TIMS techniques: Impact for their geological interpretation, J. Anal. Atom. Spectrom., 29, 1618–1629, https://doi.org/10.1039/C4JA00102H, 2014. a
Wendt, I. and Carl, C.: dating of discordant 0.1 Ma old secondary U minerals, Earth Planet. Sc. Lett., 73, 278–284, 1985. a, b, c, d
Wendt, I. and Carl, C.: The statistical distribution of the mean squared weighted deviation, Chemical Geology: Isotope Geoscience section, 86, 275–285, https://doi.org/10.1016/0168-9622(91)90010-T, 1991.
Williams, I. S.: U-Th-Pb geochronology by ion microprobe, in: Applications of Microanalytical Techniques to Understanding Mineralizing Processes, edited by: McKibben, M. A., Shanks III, W. C., and Ridley, W. I., Review of Econonomic Geolology, 7, 1–35, 1998. a
Woodhead, J. and Pickering, R.: Beyond 500ka: Progress and Prospects in the U-Pb chronology of speleothems, and their application to studies in palaeoclimate, human evolution, biodiversity and tectonics, Chem. Geol., 322–323, 290–299, https://doi.org/10.1016/j.chemgeo.2012.06.017, 2012. a
Woodhead, J., Hellstrom, J., Maas, R., Drysdale, R., Zanchetta, G., Devine, P., and Taylor, E.: U–Pb Geochronology of speleothems by MC-ICPMS, Quat. Geochronol., 1, 208–221, https://doi.org/10.1016/j.quageo.2006.08.002, 2006. a, b, c
Woodhead, J., Hellstrom, J., Pickering, R., Drysdale, R., Paul, B., Bajo, P.: U and Pb variability in older speleothems and strategies for their chronology, Quat. Geochronol., 14, 105–113, https://doi.org/10.1016/j.quageo.2012.02.028, 2012. a, b, c
York, D.: Least-squares fitting of a straight line with correlated errors, Earth Planet. Sc. Lett., 5, 320–324, 1969. a
York, D., Evensen, N. M., Martínez, M. L., and De Basabe Delgado, J.: Unified equations for the slope, intercept, and standard errors of the best straight line, Am. J. Phys., 72, 367–375, https://doi.org/10.1119/1.1632486, 2004. a
For the 238U–206Pb decay series, the assumption inherent in this approach that 226Ra remains fixed at equilibrium with 230Th can lead to inaccuracy of up to thousands of years when is significantly less than or greater than 1.
The equation numbers here refer to those in Powell et al. (2020).
- Abstract
- Introduction
- Software overview
- Disequilibrium U–Pb age calculations
- Linear regression and weighted average age protocols
- Age uncertainty propagation
- Data visualisation and plotting
-
DQPBusage examples - Availability and distribution
- Conclusion
-
Appendix A:
spinerobust weighted average -
Appendix B:
spineweighted average s simulations - Appendix C: Robust model 2
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
daughterisotopes in the uranium-series decay chain. DQPB is open-source software that allows users to easily perform such calculations for a variety of sample types and produce publication-ready graphical outputs of the resulting age information.
- Abstract
- Introduction
- Software overview
- Disequilibrium U–Pb age calculations
- Linear regression and weighted average age protocols
- Age uncertainty propagation
- Data visualisation and plotting
-
DQPBusage examples - Availability and distribution
- Conclusion
-
Appendix A:
spinerobust weighted average -
Appendix B:
spineweighted average s simulations - Appendix C: Robust model 2
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement