the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Jul 2020
| 02 Jul 2020
Technical note: A prototype transparent-middle-layer data management and analysis infrastructure for cosmogenic-nuclide exposure dating
Greg Balco
Geologic dating methods for the most part do not directly measure ages. Instead, interpreting a geochemical observation as a geologically useful parameter – an age or a rate – requires an interpretive middle layer of calculations and supporting data sets. These are the subject of active research and evolve rapidly, so any synoptic analysis requires repeated recalculation of large numbers of ages from a growing data set of raw observations, using a constantly improving calculation method. Many important applications of geochronology involve regional or global analyses of large and growing data sets, so this characteristic is an obstacle to progress in these applications. This paper describes the ICE-D (Informal Cosmogenic-Nuclide Exposure-age Database) database project, a prototype computational infrastructure for dealing with this obstacle in one geochronological application – cosmogenic-nuclide exposure dating – that aims to enable visualization or analysis of diverse data sets by making middle-layer calculations dynamic and transparent to the user. An important aspect of this concept is that it is designed as a forward-looking research tool rather than a backward-looking archive: only observational data (which do not become obsolete) are stored, and derived data (which become obsolete as soon as the middle-layer calculations are improved) are not stored but instead calculated dynamically at the time data are needed by an analysis application. This minimizes “lock-in” effects associated with archiving derived results subject to rapid obsolescence and allows assimilation of both new observational data and improvements to middle-layer calculations without creating additional overhead at the level of the analysis application.
- Article
(615 KB) - Full-text XML
- BibTeX
- EndNote





Geologic dating methods, saving a few exceptions like varve or tree ring counting, do not directly measure ages or time spans. Instead, the actual observation is typically a geochemical measurement, like a nuclide concentration or isotope ratio. Interpreting the measurement as a geologically useful parameter such as an age or rate then requires some sort of calculation and a variety of independently measured or assumed data such as radioactive decay constants, initial compositions or ratios, nuclide production rates, or nuclear cross sections (Fig. 1). These elements form a “middle layer” between the direct observations and the geological information derived from the observations. Middle-layer calculations present a problem for management and analysis of geochemical data because they constantly change as the calculation methods improve and new measurements of the other parameters become available. Even though the geochemical measurements themselves in archived or previously published studies are valid indefinitely, the derived ages become obsolete. This is an obstacle for analysis of geochronological data collected over a long period of time or, sometimes, from multiple laboratories or research groups who have different approaches to middle-layer calculations, because any comparison requires repeatedly recalculating all the derived ages from source data using a common method. This paper describes a prototype computational infrastructure for dealing with this obstacle in one geochronological application – cosmogenic-nuclide exposure dating – that is intended to enable synoptic analysis of diverse data sets by making middle-layer calculations dynamic and transparent to the user.
Cosmogenic-nuclide exposure dating is a geologic dating method that relies on the production of rare nuclides by cosmic-ray interactions with rocks and minerals at the Earth's surface. As the cosmic-ray flux is nearly entirely stopped in the first few meters below the surface, the nuclide concentration in a surface sample is related to the length of time that the sample has been exposed at the surface. This enables many applications in dating geologic events and measuring rates of geologic processes that transport rocks or minerals from the subsurface to the surface or from the surface into the subsurface (see review in Dunai, 2010). The most common of these is “exposure dating” of landforms and surficial deposits to determine, for example, the timing of glacier and ice sheet advances and retreats (e.g., Balco, 2011; Jomelli et al., 2014; Johnson et al., 2014; Schaefer et al., 2016) or fault slip rates and earthquake recurrence intervals (e.g, Mohadjer et al., 2017; Cowie et al., 2017; Blisniuk et al., 2010).
The observable data for exposure-dating applications are (i) measurements of the concentrations in common minerals of trace nuclides that are diagnostic of cosmic-ray exposure, for example, beryllium-10, aluminum-26, or helium-3, and (ii) ancillary data describing the location, geometry, and physical and chemical properties of the sample. Interpreting these measurements as the exposure age of a rock surface is simple in principle: one measures the concentration of one of these nuclides, estimates the rate at which it is produced by cosmic-ray interactions, and divides the concentration (e.g., atoms g−1) by the production rate () to obtain the exposure age (yr). It is much more complex in practice, because the cosmic-ray flux (and therefore the production rate) varies with position in the atmosphere and the Earth's magnetic field, and the production rate also depends on the chemistry and physical properties of the mineral and the rock matrix. Production rate calculations are geographically specific, temporally implicit (because the Earth's magnetic field changes over time), and require not only a model of the cosmic-ray flux throughout the Earth's atmosphere but also an array of additional data including atmospheric density models, paleomagnetic field reconstructions, nuclear interaction cross sections, and others. In addition, production rate models are empirically tuned using sets of “calibration data”, which are nuclide concentration measurements from sites whose true exposure age is independently known.
The middle layer for exposure dating, therefore, includes physical models for geographic and temporal variation in the production rate, numerical solution methods, geophysical and climatological data sets, physical constants measured in laboratory experiments, and calibration data. All these elements are the subject of active research: new production rate scaling models and magnetic field reconstructions are developed every 1–3 years, and several new calibration data sets are published each year. The result of this continuous development is that nearly all cosmogenic-nuclide exposure ages in published literature have been calculated with production rate models, physical parameters, or calibration data sets that are now obsolete.
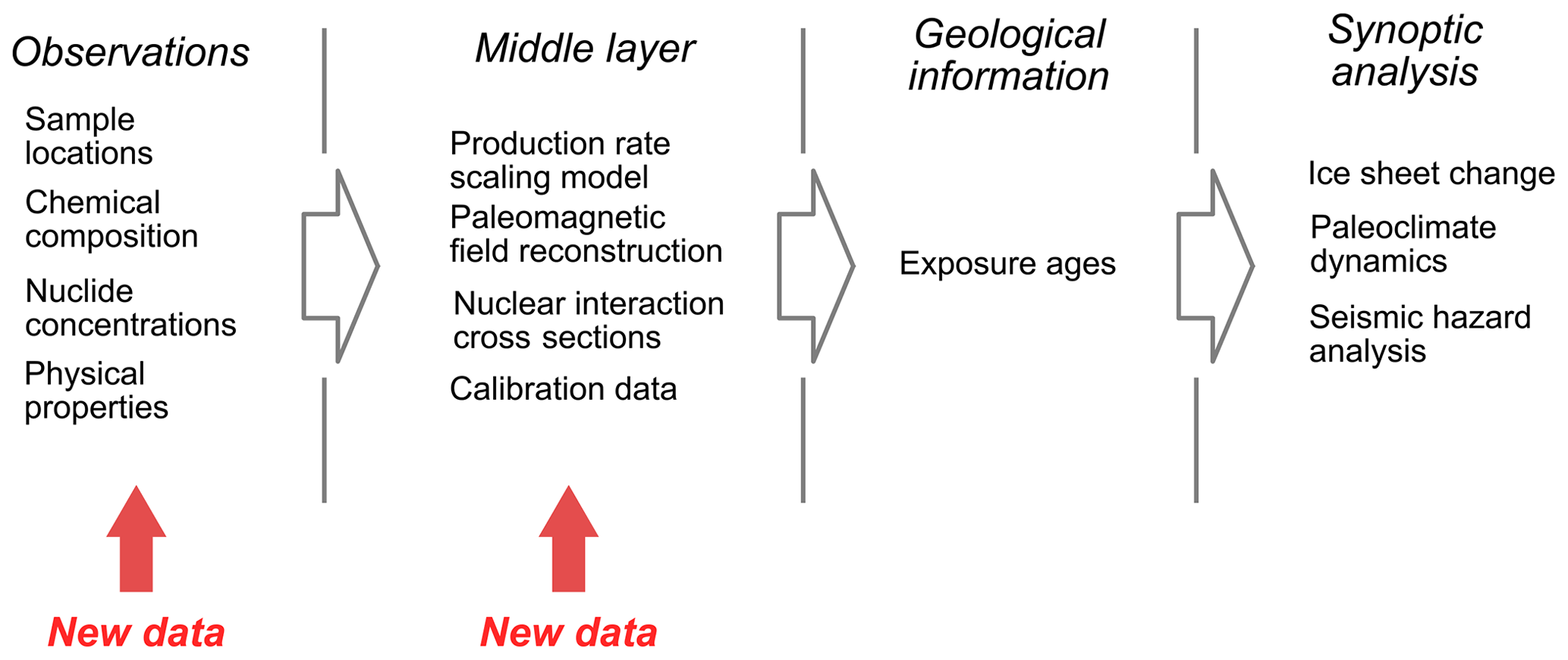
Figure 1Conceptual workflow for applications of cosmogenic-nuclide exposure dating (or, in principle, nearly any other field of geochronology). Any large-scale analysis of ages or process rates needs to continually assimilate a growing observational data set and improving middle-layer calculations or else it will be immediately obsolete.
It is unusual for middle-layer improvements to completely falsify or supersede the conclusions of previous research, but it is possible. For example, one common application of exposure dating aims to associate landforms deposited by glacier advances or retreats during the past ∼25 000 years with abrupt climate changes that occurred during that period (e.g., Balco, 2020, and references therein). Because some of these climate changes are separated by only hundreds or thousands of years, improvements in the middle-layer calculations that change production rate estimates by only a few percent can significantly change the correlation between climate events and exposure-dated landforms (see, for example, discussion and examples in Balco, 2011). Regardless of the application, however, any use of published data that are more than 1 or 2 years old, or any comparison of data generated at different times or by different research groups, requires complete recalculation of exposure ages from the raw data. As there are tens of thousands of exposure-age measurements in the published literature, this is a major challenge to the use of these data for any sort of synoptic research. This is important because many of the most valuable uses of exposure dating involve large, geographically widespread data sets applied to, for example, analysis of regional and global glacier change (e.g., Young et al., 2011; Jomelli et al., 2011, 2014; Shakun et al., 2015; Heyman et al., 2016) or analysis of ice sheet change and sea level impacts (e.g., Clark et al., 2009; Whitehouse et al., 2012; Nichols et al., 2019).
At present, middle-layer calculations for exposure dating most commonly utilize “online exposure age calculators” developed by, e.g., Balco et al. (2008), Ma et al. (2007), Marrero et al. (2016), or Martin et al. (2017) that are online forms accessible by a web browser into which one can paste sample information and cosmogenic-nuclide concentrations. The web server executes a script that carries out production rate and exposure-age calculations, and returns results formatted so as to be easily pasted into a spreadsheet. The typical workflow for comparison or analysis of exposure-age data relies on manual, asynchronous use of one or more of these services, in which researchers (i) maintain a spreadsheet of their own and previously published observational/analytical data, (ii) cut-and-paste from this spreadsheet into an online calculator, (iii) cut-and-paste calculator results back into the spreadsheet,and (iv) proceed with analysis of the results. Although the ability to use the online calculators in this way to produce an internally consistent set of results has been valuable in making synthesis of large data sets drawn from multiple sources possible at all, this procedure creates redundancy and inconsistency among separate compilations by many researchers; relies on proprietary data compilations that are, in general, not available for public access and validation; interposes many manual data manipulation steps between data acquisition and downstream analysis; creates a “lock-in” effect in which the effort required to recalculate hundreds or thousands of exposure ages using one scaling method is a disincentive to experimenting with others; and makes it difficult and time-consuming to assimilate new data into either the source data set or the middle-layer calculations.
These disadvantages of the current best-practice approach of manual, asynchronous use of the online exposure age calculators could be corrected, and synoptic visualization and analysis of exposure-age data better enabled, by a data management and computational infrastructure having the following elements.
-
A data layer: a single source of observational data that can be publicly viewed and evaluated, is up to date, is programmatically accessible to a wide variety of software using a standard application program interface (API), and is generally agreed upon to be a fairly complete and accurate record of past studies and publications, beneath
-
a “transparent” middle layer that dynamically calculates geologically useful results, in this case exposure ages, from observational data using an up-to-date calculation method or methods and serves these results via a simple API to
-
an analysis layer, which could be any Earth science application that needs the complete data set of exposure ages for analysis, visualization, or interpretation.
A transparent middle layer is simply an implementation in which middle-layer calculations are fast enough to be performed dynamically and without any user effort at the time data are requested by an application in the analysis layer. The key property of this structure that a transparent middle layer makes possible is that only observational data (which do not become obsolete) are stored. Derived data (which become obsolete whenever the middle-layer calculations are improved) are not stored but instead calculated dynamically when they are needed. This eliminates unnecessary effort and the associated lock-in effect created by manual, asynchronous application of the middle-layer calculations to locally stored data by individual users and allows continual assimilation of new data or methods into both the data layer and middle layer without creating additional overhead at the level of the analysis application. Potentially, this structure also removes the necessity for redundant data compilation by individual researchers by decoupling agreed-upon observational data (which are the same no matter the opinions or goals of the individual researcher and therefore can be incorporated into a single shared compilation) from calculations or analyses based on those data (which require judgements and decisions on the part of researchers, and therefore would not typically be agreed upon by all users). The subsequent sections of this paper describe the ICE-D (Informal Cosmogenic-Nuclide Exposure-age Database) infrastructure, a prototype implementation of this concept.
The ICE-D transparent-middle-layer infrastructure prototype includes example implementations of all three layers in the transparent-middle-layer architecture. It consists of (i) a networked database server storing observational data needed to compute exposure ages, (ii) a networked Linux server that performs middle-layer calculations with MATLAB/Octave code used in version 3 of the online exposure age calculator described by Balco et al. (2008) and subsequently updated, and (iii) a web server that responds to user requests by acquiring data from the database server, passing the data to the middle-layer server for calculation of exposure ages, and returning observations, derived exposure ages, and some related interpretive information to the user (Fig. 2). The effect is that a user interacting with the web server can browse and work with large data sets of exposure ages, originally collected and published by many researchers over several decades, without the necessity of managing the data set or repeatedly recalculating all the exposure ages using a common method. Data management and middle-layer calculations are transparent to the user, allowing focus on data visualization, discovery, and analysis.

Figure 2Generalized topology of the prototype ICE-D infrastructure compared to conventional manual, asynchronous use of online exposure age calculators. Cloud computing services interact to supply raw data, calculated exposure ages, and other derived products to users as needed for different levels of analysis.
The ICE-D prototype relies on cloud computing services available at low or zero cost from Google, Amazon Web Services, or other vendors; the current implementation uses Google Cloud Services (https://cloud.google.com, last access: 29 June 2020). The data layer is a MySQL database server provided by the Google Cloud SQL service. The middle-layer is a virtual machine on the Google Compute Engine service running CentOS 7 and the Octave code implementation of the online exposure age calculator, with a new API that facilitates programmatic use of the server. The web server that provides an example of a visualization/analysis layer is Python code running on the Google App Engine framework.
4.1 The example data layer
The purpose of the data layer is to store and serve observational data needed to calculate exposure ages, mainly including nuclide concentrations and the location, physical properties, and chemical properties of samples. It also includes some information useful for downstream analysis: for example, in a database containing exposure ages from glacial landforms, multiple samples from the same landform are grouped so as to signal that multiple ages can be averaged or otherwise combined to yield a better exposure age for the landform. The example database has a standard relational database structure, with a series of tables containing information about landforms, samples collected from landforms, and geochemical measurements on samples. Additional data tables relate samples to publications, sources of research funding, and any digital resource with a URL (field and laboratory photos, detailed reports of laboratory analyses, etc.). It is similar to the database for cosmogenic-nuclide production rate calibration data already described by Martin et al. (2017).
In contrast to other services that aim to archive geochemical or geochronological data, the ICE-D database is not structured as a single entity designed to store any cosmogenic-nuclide exposure age data regardless of application but instead consists of several separate focus area databases designed to contain restricted collections of exposure-age data needed for specific synoptic analyses. For example, ICE-D:ANTARCTICA (http://antarctica.ice-d.org, last access: 29 June 2020) contains nearly all known exposure-age data collected from the Antarctic continent, the complete data set of which is important in reconstructing past changes in the extent and thickness of the Antarctic ice sheets. ICE-D:GREENLAND (http://greenland.ice-d.org, last access: 29 June 2020) has a similar collection of data applicable to reconstructing past changes in the Greenland Ice Sheet. ICE-D:ALPINE (http://alpine.ice-d.org, last access: 29 June 2020) contains the majority of published exposure-age data from mountain glacier landforms worldwide, which in the aggregate are useful for paleoclimate reconstruction or diagnosis. The advantage of this focus-area approach is that developing relatively small (∼500 measurements for ICE-D:GREENLAND; ∼4000 for ICE-D:ANTARCTICA; ∼10 000 for ICE-D:ALPINE) data sets tailored to specific synoptic analysis applications enables a database project to become scientifically useful relatively quickly. The same number of measurements distributed among all possible global applications of exposure-dating research would likely result in many incomplete and not-particularly-useful data sets.
4.2 The example middle layer
The middle-layer calculations utilize version 3 of the online exposure age calculators originally described by Balco et al. (2008) and subsequently updated. Major improvements in version 3 in comparison to earlier versions described in the original paper include (i) an implementation of the production rate scaling method of Lifton et al. (2014) and Lifton (2016); (ii) a new API that returns exposure-age data as a compact XML representation rather than a web page, which facilitates programmatic use of the server, and (iii) many improvements in calculation speed relative to earlier versions and in comparison to other online exposure age calculators. The speed improvements are primarily derived from simple approximations for nuclide production by cosmic-ray muons (Balco, 2017) and extensive use of precalculated look-up tables instead of analytical or numerical formulae in the production rate scaling models. In principle, any one of the available online exposure age calculators, or all of them, could occupy the middle layer in this structure. In practice, however, the calculator code needs to (i) have standard programmatic interfaces for data input and output and also (ii) run fast enough that the dynamic exposure age calculations are transparent to the user. At present, CREp (which requires upload of a spreadsheet file for input) and CRONUScalc (which returns output asynchronously via email) would require software changes to meet these needs. Other code designed for exposure-age calculations but not associated with online calculators (Zweck et al., 2012; Ploskey, 2018) could most likely be used with minor modifications.
4.3 The example analysis and visualization layer
The ICE-D web server is a simple example of the type of tool that could occupy the analysis and visualization layer. For the ICE-D:ANTARCTICA, ICE-D:GREENLAND, and ICE-D:ALPINE databases, the website provides a browse tree that allows one to view observational data and derived exposure ages for samples individually or grouped by, for example, geographic region, landform, or publication. Views of samples or groups of samples include, in various combinations, detailed reports of observational data recorded in the database, exposure ages calculated using one or more production rate scaling methods, and some examples of interpretive products such as analysis of the distribution of exposure ages on a particular landform (as is, for example, useful for glacial moraines in the ICE-D:ALPINE database) or age–elevation relationships for clusters of samples (as is useful for ice sheet thickness change reconstructions using the ICE-D:ANTARCTICA database). Thus, the prototype transparent-middle-layer implementation replaces many aspects of the conventional practice of manual, asynchronous use of locally stored spreadsheets and the online exposure age calculators, while also enabling continuous data assimilation and removing the need for each user to maintain a separate copy of the data set or keep exposure-age calculations up to date.
The prototype infrastructure also allows use of the transparent-middle-layer architecture for many other analysis applications. Any analysis of exposure-age data that would conventionally operate on a static, locally stored spreadsheet or data file of previously calculated ages can instead interact with the database and middle-layer servers to dynamically obtain an up-to-date data set of exposure ages at the time of analysis. Again, this allows the user to focus on the overall analysis and not on database maintenance and age recalculation tasks. In addition, if the analysis is structured as a program or script that acts on the current state of the database, rather than a one-time calculation in a static spreadsheet, the analysis can be continually updated to assimilate additions or improvements to the data layer and the middle-layer calculations. For example, Balco (2020) showed some simple analyses of the age distribution of alpine glacier moraines worldwide. These analyses are performed by a MATLAB script that remotely queries the ICE-D:ALPINE database and the online exposure age calculator, so new data can be assimilated into the analyses simply by executing the script again. This script, like the prototype web server, is an example of one of the many possible applications that could occupy the analysis and visualization layer. Another example is that the prototype infrastructure facilitates use of exposure-age data in geographic analysis applications. At present, the web server provides geolocated sample information in KML format to embedded map services that are displayed in web pages and used as a browsing interface, but it would also be possible to serve both sample information and derived exposure ages to desktop geographic information system software. In the transparent-middle-layer infrastructure model, any number of different applications could occupy the analysis and visualization layer and rely on the same data-layer and middle-layer elements.
An often noted obstacle to participation in community data management infrastructure (e.g, Fleischer and Jannaschk, 2011; Van Noorden, 2013; Fowler, 2016) is the conflict between the broad, generalized incentive for an overall research community to develop centralized infrastructure and the immediate incentives of researchers who might, for example, view individually authored publications as more critical to career development objectives. The transparent-middle-layer model for data management has several features that could contribute to resolving this conflict. First, as discussed above, the separation of agreed-upon observational data from interpretive calculations or analysis makes the data compilation itself agnostic with respect to differences of approach or opinion among researchers, thereby reducing potential disincentives to participation in database development. Researchers with different approaches could simply develop different middle-layer and analysis-layer elements. Second, from the perspective of an individual researcher, the transparent-middle-layer infrastructure can make it substantially faster and easier to carry out time-consuming or difficult tasks (e.g., statistical analysis, generating statistical or graphical comparisons of new and existing data, comparing data with model predictions) that are required to achieve individual goals (e.g., writing successful proposals or publishing high-impact papers). In fact, more than 25 % of sample records in the ICE-D:ANTARCTICA database at this writing are unpublished data incorporated at the request of a number of researchers, and this may be evidence that the ability to use the analysis layer in tasks such as paper writing, proposal preparation, or sharing data with collaborators provides a positive incentive for user engagement with the project. User engagement with centralized data management systems should represent a trade – users provide a service to the community by making data available, and in exchange they are provided with services that help them to fulfill their own individual goals faster, better, and more easily. A transparent-middle-layer infrastructure can facilitate this exchange.
Computer code for version 3 of the online exposure age calculators and the ICE-D web server is lodged in Google Cloud source repositories. Because no security evaluation has been conducted on this code, read access is available by request from the author. This code is continually updated, and the purpose of this paper is to describe the overall architecture of the system and not a specific version or snapshot.
Greg Balco is an editor of Geochronology.
Pierre-Henri Blard, Shaun Eaves, Brent Goehring, Jakob Heyman, Alan Hidy, Maggie Jackson, Ben Laabs, Jennifer Lamp, Alia Lesnek, Keir Nichols, Sourav Saha, Irene Schimmelpfennig, Perry Spector, and Joe Tulenko helped develop the ICE-D:ANTARCTICA, ICE-D:GREENLAND, and ICE-D:ALPINE databases. Perry Spector as well as the Polar Geospatial Center at the University of Minnesota contributed to developing geographic browsing interfaces for both databases.
This work was supported in part by the Ann and Gordon Getty Foundation.
This paper was edited by Hella Wittmann-Oelze and reviewed by Sebastian Kreutzer and Richard Selwyn Jones.
Balco, G.: Contributions and unrealized potential contributions of cosmogenic-nuclide exposure dating to glacier chronology, 1990–2010, Quaternary Sci. Rev., 30, 3–27, 2011. a, b
Balco, G.: Production rate calculations for cosmic-ray-muon-produced 10Be and 26Al benchmarked against geological calibration data, Quat. Geochronol., 39, 150–173, 2017. a
Balco, G.: Glacier Change and Paleoclimate Applications of Cosmogenic-Nuclide Exposure Dating, Annu. Rev. Earth Pl. Sc., 48, 21–48, https://doi.org/10.1146/annurev-earth-081619-052609, 2020. a, b
Balco, G., Stone, J., Lifton, N., and Dunai, T.: A complete and easily accessible means of calculating surface exposure ages or erosion rates from 10Be and 26Al measurements, Quat. Geochronol., 3, 174–195, 2008. a, b, c
Blisniuk, K., Rockwell, T., Owen, L. A., Oskin, M., Lippincott, C., Caffee, M. W., and Dortch, J.: Late Quaternary slip rate gradient defined using high-resolution topography and 10Be dating of offset landforms on the southern San Jacinto fault zone, California, J. Geophys. Res.-Sol. Ea., 115, B08401, https://doi.org/10.1029/2009JB006346, 2010. a
Clark, P., Dyke, A., Shakun, J., Carlson, A., Clark, J., Wohlfarth, B., Mitrovica, J., Hostetler, S., and McCabe, A.: The last glacial maximum, Science, 325, 710–714, 2009. a
Cowie, P., Phillips, R., Roberts, G. P., McCaffrey, K., Zijerveld, L., Gregory, L., Walker, J. F., Wedmore, L., Dunai, T., Binnie, S., and Freeman, S. P. H. T.: Orogen-scale uplift in the central Italian Apennines drives episodic behaviour of earthquake faults, Sci. Rep., 7, 44858, https://doi.org/10.1038/srep44858, 2017. a
Dunai, T.: Cosmogenic Nuclides: Principles, Concepts, and Applications in the Earth Surface Sciences, Cambridge University Press, Cambridge, UK, 2010. a
Fleischer, D. and Jannaschk, K.: A path to filled archives, Nat. Geosci., 4, 575–576, 2011. a
Fowler, R.: Embracing open data in field-driven sciences, Eos T. Am. Geophys. Un., 97, 12–13, 2016. a
Heyman, J., Applegate, P. J., Blomdin, R., Gribenski, N., Harbor, J. M., and Stroeven, A. P.: Boulder height–exposure age relationships from a global glacial 10Be compilation, Quat. Geochronol., 34, 1–11, 2016. a
Johnson, J. S., Bentley, M. J., Smith, J. A., Finkel, R., Rood, D., Gohl, K., Balco, G., Larter, R. D., and Schaefer, J.: Rapid thinning of Pine Island Glacier in the early Holocene, Science, 343, 999–1001, 2014. a
Jomelli, V., Khodri, M., Favier, V., Brunstein, D., Ledru, M.-P., Wagnon, P., Blard, P.-H., Sicart, J.-E., Braucher, R., Grancher, D., and Bourlès, D. L.: Irregular tropical glacier retreat over the Holocene epoch driven by progressive warming, Nature, 474, 196–199, 2011. a
Jomelli, V., Favier, V., Vuille, M., Braucher, R., Martin, L., Blard, P.-H., Colose, C., Brunstein, D., He, F., Khodri, M., and Bourlès, D. L.: A major advance of tropical Andean glaciers during the Antarctic cold reversal, Nature, 513, 224–228, 2014. a, b
Lifton, N.: Implications of two Holocene time-dependent geomagnetic models for cosmogenic nuclide production rate scaling, Earth Planet. Sc. Lett., 433, 257–268, 2016. a
Lifton, N., Sato, T., and Dunai, T. J.: Scaling in situ cosmogenic nuclide production rates using analytical approximations to atmospheric cosmic-ray fluxes, Earth Planet. Sc. Lett., 386, 149–160, 2014. a
Ma, X., Li, Y., Bourgeois, M., Caffee, M., Elmore, D., Granger, D., Muzikar, P., and Smith, P.: WebCN: A web-based computation tool for in situ-produced cosmogenic nuclides, Nucl. Instrum. Meth. B, 259, 646–652, 2007. a
Marrero, S. M., Phillips, F. M., Borchers, B., Lifton, N., Aumer, R., and Balco, G.: Cosmogenic nuclide systematics and the CRONUScalc program, Quat. Geochronol., 31, 160–187, 2016. a
Martin, L., Blard, P.-H., Balco, G., Lavé, J., Delunel, R., Lifton, N., and Laurent, V.: The CREp program and the ICE-D production rate calibration database: A fully parameterizable and updated online tool to compute cosmic-ray exposure ages, Quat. Geochronol., 38, 25–49, 2017. a, b
Mohadjer, S., Ehlers, T. A., Bendick, R., and Mutz, S. G.: Review of GPS and Quaternary fault slip rates in the Himalaya-Tibet orogen, Earth-Sci. Rev., 174, 39–52, 2017. a
Nichols, K. A., Goehring, B. M., Balco, G., Johnson, J. S., Hein, A. S., and Todd, C.: New Last Glacial Maximum ice thickness constraints for the Weddell Sea Embayment, Antarctica, The Cryosphere, 13, 2935–2951, https://doi.org/10.5194/tc-13-2935-2019, 2019. a
Ploskey, Z.: Library for modeling cosmogenic nuclide accumulation and decay during arbitrary exposure, erosion and burial scenarios, available at: https://github.com/zploskey/cosmogenic (last access: 29 June 2020), 2018. a
Schaefer, J. M., Finkel, R. C., Balco, G., Alley, R. B., Caffee, M. W., Briner, J. P., Young, N. E., Gow, A. J., and Schwartz, R.: Greenland was nearly ice-free for extended periods during the Pleistocene, Nature, 540, 252–255, 2016. a
Shakun, J. D., Clark, P. U., He, F., Lifton, N. A., Liu, Z., and Otto-Bliesner, B. L.: Regional and global forcing of glacier retreat during the last deglaciation, Nat. Commun., 6, 1–7, 2015. a
Van Noorden, R.: Data-sharing: Everything on display, Nature, 500, 243–245, 2013. a
Whitehouse, P. L., Bentley, M. J., and Le Brocq, A. M.: A deglacial model for Antarctica: geological constraints and glaciological modelling as a basis for a new model of Antarctic glacial isostatic adjustment, Quaternary Sci. Rev., 32, 1–24, 2012. a
Young, N. E., Briner, J. P., Leonard, E. M., Licciardi, J. M., and Lee, K.: Assessing climatic and nonclimatic forcing of Pinedale glaciation and deglaciation in the western United States, Geology, 39, 171–174, 2011. a
Zweck, C., Zreda, M., Anderson, K. M., and Bradley, E.: The theoretical basis of ACE, an Age Calculation Engine for cosmogenic nuclides, Chem. Geol., 291, 199–205, 2012. a
- Abstract
- Interpretive middle-layer calculations in geochronology
- Middle-layer calculations in cosmogenic-nuclide exposure dating
- A transparent-middle-layer infrastructure
- The ICE-D implementation
- Social engineering aspects of the transparent-middle-layer concept
- Code availability
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Interpretive middle-layer calculations in geochronology
- Middle-layer calculations in cosmogenic-nuclide exposure dating
- A transparent-middle-layer infrastructure
- The ICE-D implementation
- Social engineering aspects of the transparent-middle-layer concept
- Code availability
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References