the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 11 May 2020
| 11 May 2020
Unifying the U–Pb and Th–Pb methods: joint isochron regression and common Pb correction
The actinide elements U and Th undergo radioactive decay to three isotopes of Pb, forming the basis of three coupled geochronometers. The 206Pb ∕238U and 207Pb ∕235U decay systems are routinely combined to improve accuracy. Joint consideration with the 208Pb ∕232Th decay system is less common. This paper aims to change this. Co-measured 208Pb ∕232Th is particularly useful for discordant samples containing variable amounts of non-radiogenic (“common”) Pb.
The paper presents a maximum likelihood algorithm for joint isochron regression of the 206Pb ∕238Pb, 207Pb ∕235Pb and 208Pb ∕232Th chronometers. Given a set of cogenetic samples, this algorithm estimates the common Pb composition and concordia intercept age. U–Th–Pb data can be visualised on a conventional Wetherill or Tera–Wasserburg concordia diagram, or on a 208Pb ∕232Th vs. 206Pb ∕238U plot. Alternatively, the results of the new discordia regression algorithm can also be visualised as a 208Pbc ∕206Pb vs. 238U ∕206Pb or 208Pbc ∕207Pb vs. 235U ∕206Pb isochron, where 208Pbc represents the common 208Pb component. In its most general form, the algorithm accounts for the uncertainties of all isotopic ratios involved, including the 232Th ∕238U ratio, as well as the systematic uncertainties associated with the decay constants and the 238U ∕235U ratio. However, numerical stability is greatly improved when the dependency on the 232Th ∕238U-ratio uncertainty is dropped.
For detrital minerals, it is generally not safe to assume a shared common Pb composition and concordia intercept age. In this case, the regression method must be modified by tying it to a terrestrial Pb evolution model. Thus, also detrital common Pb correction can be formulated in a maximum likelihood sense.
The new method was applied to three published datasets, including low Th∕U carbonates, high Th∕U allanites and overdispersed monazites. The carbonate example illustrates how the method achieves a more precise common Pb correction than a conventional 207Pb-based approach does. The allanite sample shows the significant gain in both precision and accuracy that is made when the Th–Pb decay system is jointly considered with the U–Pb system. Finally, the monazite example is used to illustrate how the regression algorithm can be modified to include an overdispersion parameter.
All the parameters in the discordia regression method (including the
age and the overdispersion parameter) are strictly positive
quantities that exhibit skewed error distributions near zero. This
skewness can be accounted for using the profile log-likelihood
method or by recasting the regression algorithm in terms of
logarithmic quantities. Both approaches yield realistic asymmetric
confidence intervals for the model parameters. The new algorithm is
flexible enough that it can accommodate disequilibrium corrections
and intersample error correlations when these are provided by the
user. All the methods presented in this paper have been added to
the IsoplotR software package. This will hopefully
encourage geochronologists to take full advantage of the entire
U–Th–Pb decay system.
- Article
(2552 KB) - Full-text XML
- BibTeX
- EndNote





The Pb content of U-bearing minerals comprises two components:
-
Non-radiogenic (a.k.a. initial or “common”) Pb is inherited from the environment during crystallisation. It contains all of lead's four stable isotopes (204Pb, 206Pb, 207Pb and 208Pb) in fixed proportions for a given sample.
-
Radiogenic Pb is added to the common Pb after crystallisation due to the decay of U and Th. It contains only three isotopes (206Pb, 207Pb and 208Pb), which occur in variable proportions as a function of the Th∕U ratio and age.
Denoting the measured and non-radiogenic components with subscripts “m” and “c”, respectively, and assuming initial secular equilibrium, we can write
where λ38, λ35 and λ32 are the decay constants of 238U, 235U and 232Th, respectively, and t is the time elapsed since isotopic closure. In order to accurately estimate t, the common Pb composition is needed. One way to account for common Pb is to normalise all the measurements to 204Pb. For example, using the 238U–206Pb decay scheme:
Applying Eq. (5) to multiple cogenetic aliquots of the same sample defines an isochron with slope and intercept . Alternatively, and equivalently, an “inverse” isochron line can be defined as
In this case, the isochron is a line whose y intercept defines the common 204Pb ∕206Pb ratio, and the x intercept determines the radiogenic 238U ∕206Pb ratio.
The isochron concept can easily be applied to the 235U–207Pb system, by replacing 206Pb with 207Pb, 238Pb with 235Pb and λ38 with λ35 in Eqs. (5) and (6). The accuracy and precision of the calculation can be further improved by solving the 206Pb ∕238U and 207Pb ∕235U isochron equations simultaneously and requiring t to be the same in both systems. The resulting three-dimensional constrained isochron is known as a total-Pb∕U isochron (Ludwig, 1998).
In igneous samples, the conventional total-Pb∕U isochron requires isotopic data for two or more cogenetic aliquots. In the simplest case, a two-point isochron can be formed by analysing the U–Pb composition of the U-bearing phase of interest along with a cogenetic mineral devoid of U (e.g., feldspar). In detrital samples, the common Pb intercept of the isochron can be anchored to some nominal value or to a terrestrial Pb evolution model (e.g., Stacey and Kramers, 1975). Thus, the 204Pb-based total-Pb∕U isochron method is beneficial to nearly all applications of the U–Pb method.
Unfortunately, 204Pb-based common Pb correction is not always practical. First, not all mass spectrometers are able to measure 204Pb with sufficient precision and accuracy. In some inductively coupled plasma mass spectrometry (ICP-MS) instruments, the presence of an isobaric interference with 204Hg precludes accurate 204Pb measurements. And second, because 204Pb is by far the least abundant of lead's four naturally occurring isotopes, it requires the longest dwell times. For single collector instruments, this reduces the precision of the other isotopes.
To overcome these problems, alternative common Pb correction schemes have been proposed that use 207Pb or 208Pb instead of 204Pb. The semitotal-Pb∕U isochron method is based on linear regression of 206Pb–207Pb–238U data in Tera–Wasserburg space (Ludwig, 1998; Williams, 1998; Chew et al., 2011). It assumes that all the samples are cogenetic and form a simple two-component mixture between common Pb and radiogenic Pb. The common Pb then marks the intercept with the 207Pb ∕206Pb axis, and the radiogenic Pb can be obtained from the intersection of the isochron with the concordia line. The 207Pb-based common Pb correction only works if the assumption of initial concordance is valid, if 207Pb can be measured with sufficient precision, and if there is enough spread in the initial Pb∕U ratios to produce a statistically robust isochron.
Andersen (2002) introduced a 208Pb-based common Pb correction scheme that does not require initial concordance. His method assumes that U–Th–Pb discordance can be accounted for by a combination of Pb loss at a defined time and the presence of common Pb of known composition. However, in most cases, neither the timing of Pb loss nor the composition of the common Pb are known. Furthermore, the assumptions that underlie the Andersen (2002) method were tailored to the mineral zircon but do not apply so much to other minerals such as carbonates, which crystallise at low temperatures and do not experience diffusive Pb loss.
This paper introduces a isochron algorithm that uses the 232Th–208Pb decay scheme to determine the common Pb component. Unlike the Andersen (2002) method, it does not require the common Pb composition to be pre-specified but assumes that no Pb loss has occurred. The new algorithm is based on Ludwig (1998)'s total-Pb∕U isochron method but uses 208Pbc instead of 204Pb in Eq. (5):
and similarly for Eq. (6) and the 235U–207Pb equivalents of Eqs. (5) and (6).
The algorithms introduced in this paper will be illustrated using three published U–Th–Pb datasets, which showcase how the combined U–Th–Pb approach improves both the precision and accuracy of U–Pb geochronology (Sect. 4). The cases studies include a carbonate dataset of Parrish et al. (2018), an allanite dataset of Janots and Rubatto (2014) and an overdispersed monazite dataset of Gibson et al. (2016). The carbonate dataset is an example of a low Th∕U setting in which the 208Pb-based common Pb correction is more precise than a conventional 207Pb ∕206Pb-based common Pb correction. The allanite dataset is an example of a high Th∕U setting in which the 208Pb ∕232Th method offers greater precision than the U–Pb method. The Janots and Rubatto (2014) study used the Secondary Ion Mass Spectrometer (SIMS) and therefore also offers an opportunity to compare the new 208Pb method with a conventional 204Pb-based common Pb correction.
Section 5 shows how the isochron regression algorithm can
be modified to accommodate strongly skewed uncertainty distributions,
using a simple logarithmic change of variables. The
isochron algorithm assumes that all aliquots are cogenetic. However,
Sect. 6 shows how the algorithm can be adapted to
detrital samples, by tying it to the two-stage Pb evolution model of
Stacey and Kramers (1975). This procedure is similar in spirit to the
iterative algorithm of Chew et al. (2011) but uses a maximum likelihood
approach that weights the uncertainties of all isotopes in the coupled
U–Th–Pb decay system. Finally, Sect. 7 introduces
an implementation of the algorithms described herein using the
IsoplotR software package.
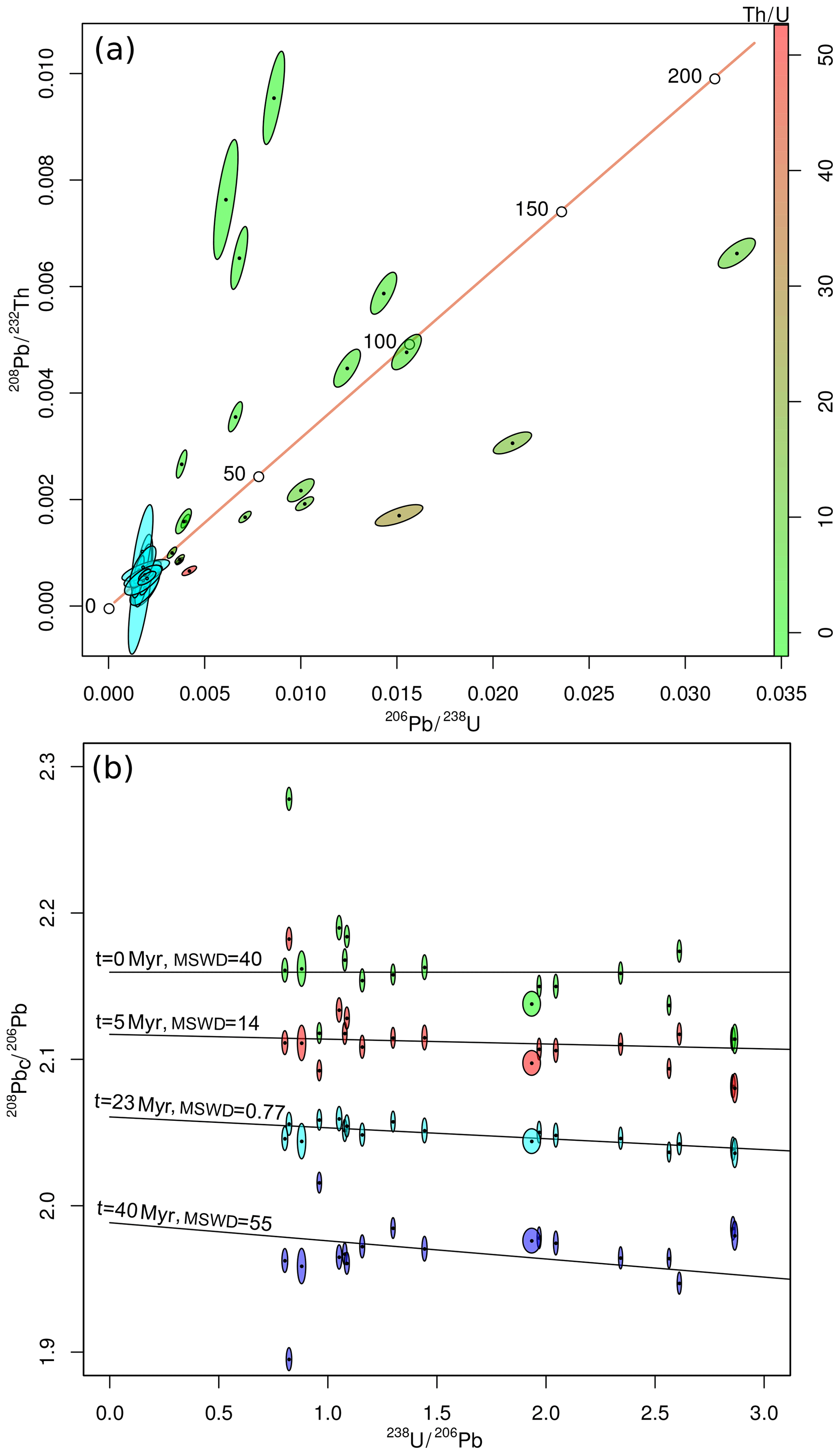
Figure 1U–Th–Pb data for allanite sample MF482 of Janots and Rubatto (2014) shown on (a) a U–Th–Pb concordia diagram and (b) a 208Pbc ∕206Pb–238U ∕206Pb isochron plot. The raw data are shown in shades of green to red on the concordia diagram, in proportion to the Th∕U ratio. The same raw data are shown as green ellipses on the isochron diagram. Red, light and dark blue ellipses show the measurements with 5, 23 and 40 Myr worth of radiogenic 208Pb removed, respectively. The misfit of the radiogenic 208Pb-corrected data around the best fit line are expressed as the mean square of the weighted deviates (MSWD; McIntyre et al., 1966) values. Error ellipses are shown at 1σ.
In conventional U–Pb geochronology, the set of concordant 206Pb ∕238U and 207Pb ∕235U ratios defines a Wetherill concordia line. Similarly, U–Th–Pb data can be visualised in 208Pb ∕232Th- vs. 206Pb ∕238U-ratio space. In the absence of common Pb, samples whose 208Pb ∕232Th ages equal their 206Pb ∕238U ages plot on a U–Th–Pb concordia line. The addition of common Pb pulls samples away from this line. Binary mixing between common Pb and radiogenic Pb forms linear trends in conventional concordia space but not in U–Th–Pb concordia space. For example the Janots and Rubatto (2014) data plot above or below the concordia line depending on the Th∕U ratio (Fig. 1a).
An alternative visualisation is to plot 208Pb ∕206Pb against 238U ∕206Pb (Fig. 1b). The radiogenic 208Pb component can be removed by rearranging Eq. (4) for 208Pbc ∕232Thm and subtracting it from [208Pb ∕232Th]m. Doing this for different values of t moves the various aliquots vertically on the diagram. Each value of t also corresponds to a radiogenic 238U ∕206Pb ratio, thus marking a point on the horizontal axis of the diagram. We can fit a line through this point and minimise the residual scatter of the data around it, using a least squares criterion such as the mean square of the weighted deviates (MSWD; McIntyre et al., 1966). For the Janots and Rubatto (2014) data, the residual scatter is minimised when t≈23 Myr (Fig. 1b). At this value, the aliquots plot along a simple binary mixture between common Pb and radiogenic Pb. This marks the best estimate for the concordia age. The corresponding common-Pb-corrected 208Pb ∕232Th–206Pb ∕238U composition is shown as a tight cluster of blue error ellipses on Fig. 1a.
In order to formalise this procedure in a mathematical sense, let us first define a number of variables. In analogy to the variable names used by Ludwig (1998), we will refer to the blank corrected isotopic ratios as X, Y, Z, W and U:
where X, Y and Z are vectors, W is a diagonal matrix, and U is a scalar; we will use Greek characters for the unknown common Pb ratios:
where α and β are scalars and γ is a vector; and finally, we will use t as the concordia age so as to satisfy Eqs. (1)–(4).
Next, we define three misfit vectors (K, L and M) containing the difference between the measured and the predicted (i.e., common plus radiogenic) isotope ratios:
This formulation is a straightforward adaptation of Ludwig (1998)'s 204Pb-based total-Pb∕U isochron equations. And like Ludwig (1998), we can then estimate t, α and β by minimising the sum of squares:
where Δ is the amalgamated misfit vector and ΔT is its transpose (i.e., ΔT=[KTLTMT]). ΣΔ is the covariance matrix of Δ, which can be estimated by error propagation:
in which 0a×b is an a×b matrix of zeros, Σx is the 4n×4n covariance matrix of the collated data measurements X, Y, Z and W; Σλ is the 4×4 covariance matrix of the decay constants and U, and Jx and Jλ are Jacobian matrices with partial derivatives of Δ with respect to the isotopic ratio measurements and the decay constants (plus U), respectively. Further details for Σx, Σλ, Jx and Jλ are provided in Appendix A.
Equation (14) can be solved for t, α and β by iterative methods, but the numerical stability of these methods is not guaranteed. Numerical stability and speed of convergence are greatly improved by removing the uncertainties of W from the data covariance matrix Σx. If the sum of squares S does not depend on the uncertainty of W, then the partial derivatives of S with respect to α, β, γ and t can be calculated manually, which greatly simplifies the optimisation. Further details about this simplified algorithm are provided in Appendix B.
The log likelihood of the isochron fit is given by
where marks the determinant of ΣΔ. The covariance matrix of the fit parameters is then obtained by inverting the matrix of second derivates of the negative log likelihood with respect to the vector γ and the scalars t, α, β. This is also known as the Fisher information matrix:
where Σγ is an n×n matrix; s[γ,t], s[γ,α] and s[γ,β] are n-element row vectors, s[t,γ], s[α,γ] and s[β,γ] are n-element column vectors, and all other elements are scalars. The second derivatives are given in Appendix C. The Fisher information matrix is best solved by block matrix inversion. This is achieved by partitioning Eq. (17) into four parts, with defining the first block.
If analytical uncertainty is the only source of data scatter around the discordia line, then the sum of squares S follows a central χ2 distribution with 2n−3 degrees of freedom (i.e., ). Normalising S by the degrees of freedom gives rise to the so-called reduced χ2 statistic, which is also known as the mean square of the weighted deviates (MSWD):
Datasets are said to be overdispersed if S is greater than the 95 % percentile of or, equivalently, if MSWD≫1 Wendt and Carl (1991). The overdispersion can either be attributed to geological scatter in the concordia intercept age t, or to excess variability in the common Pb ratios α and β. Suppose that the scatter follows a normal distribution with zero mean and let ω be the standard deviation of this distribution. Then we can redefine Eq. (15) as
where Jω is the Jacobian matrix with the partial derivatives of Δ with respect to the dispersion parameter ω. If the overdispersion is attributed to diachronous isotopic closure, then
where In×n is the n×n identity matrix.
Alternatively, if the overdispersion is attributed to excess scatter of the common Pb ratios, then
ω can then be found by plugging Eq. (19) into Eq. (16) and maximising ℒ. Like before, the uncertainty of ω is obtained by inverting the Fisher information matrix, replacing Eq. (17) with
In this case, manual calculation of the second derivatives is only possible if the overdispersion is attributed to t, with formulae shown in Appendix D. The second derivates are not tractable if the excess dispersion is assigned to α and β. In this case, the Fisher information matrix must always be calculated numerically, which can be difficult.
This section applies the U–Th–Pb isochron algorithm to two published datasets: a carbonate dataset of Parrish et al. (2018) and an allanite dataset of Janots and Rubatto (2014). Parrish et al. (2018) investigated the Palaeogene deformation history of southern England by dating calcite veins in chalk and greensand. The measurements were made by quadrupole LA-ICP-MS, for which it was not possible to measure 204Pb with sufficient precision or accuracy. Figure 2a shows the U–Pb data of one particular sample (CB-2, Isle of Wight) on a conventional Tera–Wasserburg diagram. In the absence of 204Pb, conventional data processing would apply a common Pb correction using the 207Pb-method. That is, it would infer the concordia intercept age by regression of a semitotal-Pb∕U isochron. Doing so suggests a U–Pb age of 29.72±1.23 Myr. However, this isochron exhibits significant overdispersion with respect to the analytical uncertainties (MSWD of 3.2), casting doubt on the accuracy of the date. The fit also suffers from low precision, caused by the large uncertainties of the 207Pb-measurements. These cause the error ellipses of some spots to cross over into negative 207Pb ∕206Pb space.
The Th∕U ratios of CB-2 are extremely low (< .12, as shown on the colour scale of Fig. 2). These low ratios are caused by the low solubility of Th in the vein-forming fluids. As a consequence, less than 1 % of the measured 208Pb is of radiogenic origin. At the same time, the sample contains between 2 and 20 times more 208Pb than it does 207Pb. This makes the 208Pb-based correction far more precise than the conventional 207Pb-based semitotal-Pb∕U correction. Figure 2b shows the isochron of CB-2 in 208Pbc ∕206Pb–238U ∕206Pb space. The scatter around this line is much tighter than that of the semitotal-Pb∕U fit, and the MSWD is only 2.5 despite the high precision of the added 208Pb data. The isochron intercept age has dropped to 24.43±0.84 Myr, which is significantly younger than the 207Pb-corrected date. Importantly, the two age estimates do not overlap within the stated uncertainties. The new date is close to, but not quite as young as, the 22.6±1.5 Myr value proposed by Parrish et al. (2018), which was obtained by a heuristic version of the isochron algorithm.
It is not possible to formally prove that the 208Pb-corrected date is more accurate than the 207Pb-corrected date for the carbonate dataset. However, an independent assessment of accuracy is possible for our second case study. Janots and Rubatto (2014)'s allanite dataset used SIMS instead of LA-ICP-MS, making it possible to compare a 204Pb-based common Pb correction with the new 208Pb method. Figure 3a shows the U–Pb data of one particular allanite sample (MF482) on a conventional Tera–Wasserburg concordia diagram, yielding a semitotal-Pb∕U isochron age of 22.77±5.63 Myr. This is nearly identical to Janots and Rubatto (2014)'s 207Pb-corrected 208Pb ∕206Pbc–232Th ∕206Pbc isochron age of 22.7±1.0 Myr. As before, the Th∕U ratios are shown as shades of green to red. These values range from 23 to 235, which is 3 orders of magnitude higher than Parrish et al. (2018)'s carbonate data. Consequently, most of the chronometric power of the allanite data is contained in the Th–Pb system and not in the U–Pb method. 90 %–97 % of the 208Pb is radiogenic, as opposed to 0.3 %–1.0 % of the 206Pb, and only 0.06 %–0.016 % of the 207Pb.
Figure 3b shows the Th–Pb data in 204Pb ∕208Pb–232Th ∕208Pb space, where they form an isochron with a Th–Pb age of 21.50±4.37 Myr. This agrees within error with the 207Pb-corrected U–Pb age, despite the possible presence of an unresolved isobaric interference on 204Pb (Janots and Rubatto, 2014). However, the Th–Pb isochron age has a slightly smaller uncertainty and a much lower MSWD (0.74 instead of 1.4). Combining the U–Pb and Th–Pb systems together, Fig. 3c shows allanite sample MF482 in 208Pbc ∕206Pb–238U ∕206Pb space, where it defines an 23.21±0.85 Myr isochron. This falls within the uncertainties of the U–Pb and Th–Pb age estimates but is more than 5 times more precise than the previous age estimates. An alternative visualisation of the isochron is shown in Fig. 3d. Here, the 207Pbc ∕208Pb ratio is plotted against 232Th ∕208Pb. Thus, we use the 207Pb as a common Pb indicator instead of the 204Pb used in Fig. 3b. The > 15 times greater abundance of 207Pb compared to 204Pb nearly quadruples the precision of the data, producing a tight fit around the isochron.

Figure 2(a) Semitotal-Pb∕U isochron (207Pb-based common Pb correction) for Parrish et al. (2018)'s chalk data; (b) isochron (208Pb-based common Pb correction) shown in 208Pbc ∕206Pb–238U ∕206Pb space. Colours indicate the Th∕U ratio. All uncertainties are shown at 1σ.

Figure 3(a) Semitotal-Pb∕U isochron (207Pb-based common Pb correction) for Janots and Rubatto (2014)'s allanite data; (b) conventional Pb∕Th isochron (204Pb-based common Pb correction); (c, d) isochron (208Pb-based common Pb correction) shown in 208Pbc ∕206Pb–238U ∕206Pb space (c) and 206Pbc ∕208Pb–232Th ∕208Pb space (d). Colours indicate the Th∕U ratio. All uncertainties are shown at 1σ.
All the free parameters in the regression algorithm (t, α, β and ω) are strictly positive quantities. This positivity constraint manifests itself in skewed error distributions. For example, when the four parameter algorithm of Sect. 3 is applied to datasets that exhibit little or no overdispersion (ω≈0), then the usual 2σ error bounds can cross over into physically impossible negative data space. This section of the paper introduces two ways to deal with this problem.
A first solution is to obtain asymmetric uncertainty bounds for ω using a profile likelihood approach (Galbraith, 2005; Vermeesch, 2018). First, maximise Eq. (16) for the four parameters t, α, β and ω. Denote the corresponding log-likelihood value by ℒm. Second, consider a range of values for ω around the maximum likelihood estimate. For each of these values, maximise ℒ for t, α and β whilst keeping ω fixed. Denote the corresponding log likelihood by ℒω. Finally, a 95 % confidence region for ω is obtained by collecting all the values of ω for which , where 3.85 corresponds to the 95th percentile of a χ2 distribution with one degree of freedom (Fig. 4). The same procedure can also be applied to t, α and β, in order to obtain asymmetric confidence intervals for those parameters if needed. This would be particularly useful for very young samples.
A second and more pragmatic approach to dealing with the positivity constraint is to simply redefine the regression parameters in terms of logarithmic quantities. This is done by replacing Eqs. (11), (12) and (19) with
respectively, and maximising Eq. (16) with respect to t∗, α∗, β∗ and ω∗. The standard errors for these log parameters (again obtained from the Fisher information matrix) can then be converted to asymmetric confidence intervals for t, α, β and ω. This approach yields results that are similar to those obtained using the profile log-likelihood method, as illustrated in Fig. 4 for monazite grain no. 10 in sample BHE-01 of Gibson et al. (2016). This sample experienced a diachronous crystallisation history, resulting in an overdispersed isochron fit (MSWD of 8). Quantifying the excess dispersion with a model-3 fit yields an overdispersion parameter ω=0.67 Myr with asymmetric confidence bounds of +0.48/−0.23 Myr. Besides generating realistic confidence regions, the logarithmic re-parameterisation of the likelihood function has the added benefit increasing the numerical stability of the maximum likelihood method.

Figure 4Profile log-likelihood intervals of the overdispersion parameter ω (black, left) and log (ω) (black, right) for the Gibson et al. (2016) dataset. The set of ω values whose log likelihoods fall within a range of 1.92 from the maximum value defines an asymmetric 95 % confidence interval. Alternatively, a standard symmetric confidence interval for log (ω) (grey, right) can be mapped to an asymmetric confidence interval for ω (grey, left). The two approaches yield similar results.
So far, we have assumed that all the U–Th–Pb measurements are cogenetic and share the same common Pb composition. This assumption is generally not valid for detrital minerals, which tend to contain a mixture of provenance components. In this case the different crystals in a sample are not expected to plot along a single isochron line. However, it is still possible to remove the common Pb component by making certain assumptions about its composition. One way to do this is to assume that the mineral of interest was extracted from a reservoir of known U–Th–Pb composition.
For example, using the two-stage Pb evolution model of Stacey and Kramers (1975), it is possible to predict the 206Pb ∕208Pb and 207Pb ∕208Pb ratios of the reservoir for any given time t. More specifically, if t<3.7 Ga, then
where
and
Substituting α(t) and β(t) for α and β in Eqs. (11)–(13) reduces the number of free parameters from three (α, β and t) to one (t). This provides a quick and numerically robust mechanism for common Pb correction of detrital minerals. It is the maximum likelihood equivalent of the heuristic approach used by Chew et al. (2011).
IsoplotR The algorithms presented in this paper have been implemented in the
IsoplotR software toolbox for geochronology
(Vermeesch, 2018). The easiest way to use the U–Th–Pb isochron
functions is via an online graphical user interface at http://isoplotr.london-geochron.com (last access: 4 May 2020). Alternatively, the same
functions can also be accessed from the command line, using the
R programming language (R Core Team, 2020). This section of the
paper presents some code snippets to illustrate the key functions
involved. This brief tutorial assumes that the reader has R
and IsoplotR installed on her/his computer. Further details
about this are provided by Vermeesch (2018) and on the
aforementioned website. First, we need to load IsoplotR into
R:
library(IsoplotR)
Two new data formats have been added to IsoplotR's existing
six U–Pb formats, to accommodate datasets comprising
232Th and 208Pb. Sample Ga2 of
Janots and Rubatto (2014) has been included in the IsoplotR package
as two data files (UPb7.csv and UPb8.csv).
UPb7.csv specifies the U–Th–Pb composition using the
Wetherill ratios 207Pb ∕235U,
206Pb ∕238U,
208Pb ∕232Th and
232Th ∕238U, whereas
UPb8.csv uses the Tera–Wasserburg ratios
238U ∕206Pb,
207Pb ∕206Pb,
208Pb ∕206Pb and
232Th ∕238U. The key difference
between the two formats is the strength of the internal error
correlations, which is greater for format 7 than it is for format
8. The following commands load the contents of UPb8.csv into
a variable called UPb and plot the data on a
208Pb ∕232Th
vs. 206Pb ∕238U-concordia diagram:
Performing a discordia regression and visualising the results as a 208Pbc ∕206Pb vs. 238U ∕206Pb isochron:
isochron(UPb,type=1)
which performs a three-parameter regression without
overdispersion. Accounting for overdispersion is done using the
optional model argument:
fit <- isochron(UPb,type=1,model=3)
where fit is a variable that stores the numerical
results of the isochron regression. This is a list of items that can
be inspected by typing fit at the R command
prompt. For example, the maximum likelihood estimates for t,
α, β and ω are stored in fit$par and the
covariance matrix in fit$cov. Changing type to
2 plots the regression results as a
208Pbc ∕207Pb vs. 235U ∕207Pb isochron. The
isochron results can also be visualised on the concordia diagram:
concordia(UPb,type=2,show.age=2)
where type=2 produces a Tera–Wasserburg diagram and
the show.age argument adds a three-parameter regression line
to it. Change this to show.age=4 for a four-parameter fit.
This paper introduced a algorithm for common Pb correction by joint regression of all Pb isotopes of U and Th. For samples that are low in Th (such as carbonates), 208Pb offers the most precise way to correct for common Pb, because 208Pb tends to be more abundant than both 204Pb and 207Pb. For samples that are high in Th, the 208Pb ∕232Th clock adds chronometrically valuable information to the joint U–Pb decay systems.
The ingrowth of radiogenic Pb described by
Eqs. (2)–(4) assumes initial secular
equilibrium between all the intermediate daughters in the U–Th–Pb
decay chains. The new discordia regression algorithm can be modified
to accommodate departures from this assumption. In fact, such
disequilibrium corrections have already been implemented in
IsoplotR, using the matrix derivative approach of
McLean et al. (2016). A paper detailing these calculations is in
preparation by the latter author. The disequilibrium correction is
particularly useful for applications to young carbonates, whose
initial 234U ∕238U and
230Th ∕238U activity ratios may be
far out of equilibrium.
The new discordia regression algorithm is based on the method of maximum likelihood and accounts for correlated uncertainties between variables. However, geochronological datasets are often associated with equally significant error correlations between samples (Vermeesch, 2015). The algorithm presented in this paper easily handles such correlations, which carry systematic uncertainty. These are represented by the off-diagonal terms of the covariance matrix Σx in Eq. (15). However, to use this option in practical applications will require a new generation of low-level data processing software.
This new-generation software will also need to deal with a second issue that negatively affects the accuracy of the U(–Th)–Pb method, which is apparent from Fig. 1. After removing the radiogenic 208Pb component from the Janots and Rubatto (2014) dataset, the 95 % confidence ellipse of one of the aliquots crosses over into negative 208Pb ∕232Th ratios. This nonsensical result is related to the issues discussed in Sect. 5. Isotopic data are strictly positive quantities that exhibit skewed error distributions. “Normal” statistical operations such as averaging and the calculation of 2σ confidence intervals can produce counterintuitive results when applied to such data.
In Sect. 5, the skewness of the fit parameters was removed by reformulating the regression algorithm in terms of logarithmic quantities. Similarly, Vermeesch (2015) showed that the skewness of isotopic compositions can be removed using log ratios, in the context of 40Ar ∕39Ar geochronology. McLean et al. (2016) introduced the same approach to in situ U–Pb geochronology by LA-ICP-MS. Future software development will allow analysts to export their U–Th–Pb isotopic data directly as log ratios and covariance matrices. Such a data structure can still be analysed with the new discordia regression algorithm, after a logarithmic change a variables for X, Y, Z and W in Eqs. (11), (12) and (13).
The U–Pb method is one of the most powerful and versatile methods in the geochronological toolbox. With two isotopes of the same parent (235U and 238U) decaying to two different isotopes of the same daughter (207Pb and 206Pb), the U–Pb method offers an internal quality control that is absent from most other geochronological techniques. U-bearing minerals often contain significant amounts of Th, which decays to 208Pb. However, until this day, geochronologists have not frequently used this additional parent–daughter pair to its full potential. It is hoped that the algorithm and software presented in this paper will change this situation.
The covariance matrix of the isotopic ratio measurements X, Y, Z and W is given by
where
and so forth, in which s[a]2 is the variance of a and s[a,b] is the covariance of a and b, for any a and b. Σλ is the covariance matrix of the decay constants and the 238U ∕235U ratio:
Here, the covariance terms have been set to zero, but nonzero values could also be accommodated. Finally, the Jacobian matrices Jx and Jλ are given by
and
where 1n×1 is an n-element column vector of ones.
The numerical stability of the optimisation is greatly enhanced by dropping the dependency of the sum of squares S on the uncertainty of the Th∕U ratios W. Thus, we replace Eq. (A1) by
and Eq. (A5) by the 3n×3n identity matrix (i.e., ). Let us define Ω to be the inverse covariance matrix of Δ, so that
Then, we can directly estimate γ for any given value of t, α and β, by replacing γ with in Eq. (13), so that
with
and
with
Plugging Eqs. (B3) and (B4) into Eq. (14) and rearranging yields
where
Taking the matrix derivative of S with respect to M,
Setting and solving for M,
Plugging M back into Eq. (13) yields our estimate of γ, which allows us to calculate S. The values of t, α and β that minimise S are then found by numerical methods.
Explicit formulae for the Fisher information matrix (Eq. 17) are possible for the simplified algorithm, in which the uncertainty of W is ignored:
Additional derivatives are required to propagate the uncertainty of the overdispersion parameters ω. This can only be done manually if the overdispersion is attributed to the concordia intercept age t, using the simplified model (ignoring the uncertainty of W). In that case,
with
in which Tr(∗) stands for the trace of ∗ and
Explicit formulae for the second derivatives are not available for the common-Pb-based overdispersion model. In that case, the Fisher information matrix must be computed numerically.
The datasets used in this paper were previously published by Gibson et al. (2016), Janots and Rubatto (2014) and Parrish et al. (2018).
The authors declare that they have no conflict of interest.
Pieter Vermeesch would like to thank Randy Parrish, Phil Hopley and John Cottle for stimulating discussions that prompted the writing of this paper; and Ryan Ickert and Kyle Samperton for careful reviews.
This paper was edited by Brenhin Keller and reviewed by Ryan Ickert and Kyle Samperton.
Andersen, T.: Correction of common lead in U–Pb analyses that do not report 204Pb, Chem. Geol., 192, 59–79, 2002. a, b, c
Chew, D. M., Sylvester, P. J., and Tubrett, M. N.: U–Pb and Th–Pb dating of apatite by LA-ICPMS, Chem. Geol., 280, 200–216, 2011. a, b, c
Galbraith, R. F.: Statistics for fission track analysis, CRC Press, 2005. a
Gibson, R., Godin, L., Kellett, D. A., Cottle, J. M., and Archibald, D.: Diachronous deformation along the base of the Himalayan metamorphic core, west-central Nepal, Geol. Soc. Am. Bull., 128, 860–878, 2016. a, b, c, d
Janots, E. and Rubatto, D.: U–Th–Pb dating of collision in the external Alpine domains (Urseren zone, Switzerland) using low temperature allanite and monazite, Lithos, 184, 155–166, 2014. a, b, c, d, e, f, g, h, i, j, k, l, m
Ludwig, K. R.: On the treatment of concordant uranium-lead ages, Geochim. Cosmochim. Ac., 62, 665–676, https://doi.org/10.1016/S0016-7037(98)00059-3, 1998. a, b, c, d, e, f
McIntyre, G. A., Brooks, C., Compston, W., and Turek, A.: The Statistical Assessment of Rb-Sr Isochrons, J. Geophys. Res., 71, 5459–5468, 1966. a, b
McLean, N. M., Bowring, J. F., and Gehrels, G.: Algorithms and software for U-Pb geochronology by LA-ICPMS, Geochem. Geophy. Geosy., 17, 2480–2496, 2016. a
McLean, N. M., Smith, C. J. M., Roberts, N. M. W., and Richards, D. A.: Connecting the U-Th and U-Pb Chronometers: New Algorithms and Applications, AGU Fall Meeting Abstracts, 2016. a
Parrish, R. R., Parrish, C. M., and Lasalle, S.: Vein calcite dating reveals Pyrenean orogen as cause of Paleogene deformation in southern England, J. Geol. Soc., 175, 425–442, 2018. a, b, c, d, e, f, g
R Core Team: R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria, available at: https://www.R-project.org/, last access: 28 April 2020. a
Stacey, J. and Kramers, J.: Approximation of terrestrial lead isotope evolution by a two-stage model, Earth Planet. Sc. Lett., 26, 207–221, 1975. a, b, c
Vermeesch, P.: Revised error propagation of 40Ar/39Ar data, including covariances, Geochim. Cosmochim. Ac., 171, 325–337, 2015. a, b
Vermeesch, P.: IsoplotR: a free and open toolbox for geochronology, Geosci. Front., 9, 1479–1493, 2018. a, b, c
Wendt, I. and Carl, C.: The statistical distribution of the mean squared weighted deviation, Chem. Geol., 86, 275–285, 1991. a
Williams, I. S.: U-Th-Pb geochronology by ion microprobe, Rev. Econ. Geol., 7, 1–35, 1998. a
- Abstract
- Introduction
- U–Th–Pb concordia and the isochron
- Error propagation and overdispersion
- Application to literature data
- Dealing with skewed error distributions
- Detrital samples
-
Implementation in
IsoplotR - Discussion and future developments
- Appendix A
- Appendix B
- Appendix C
- Appendix D
- Data availability
- Competing interests
- Acknowledgements
- Review statement
- References
- Abstract
- Introduction
- U–Th–Pb concordia and the isochron
- Error propagation and overdispersion
- Application to literature data
- Dealing with skewed error distributions
- Detrital samples
-
Implementation in
IsoplotR - Discussion and future developments
- Appendix A
- Appendix B
- Appendix C
- Appendix D
- Data availability
- Competing interests
- Acknowledgements
- Review statement
- References