the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 18 Jul 2024
| 18 Jul 2024
Errorchrons and anchored isochrons in IsoplotR
Isochrons are usually fitted by “York regression”, which uses a weighted least-squares approach that accounts for correlated uncertainties in both variables. Despite its tremendous popularity in modern geochronology, the York algorithm has two important limitations that reduce its utility in several applications. First, it does not provide a satisfactory mechanism to deal with so-called “errorchrons”, i.e. datasets that are overdispersed with respect to the analytical uncertainties. Second, York regression is not readily amenable to anchoring, in which either the slope or the intercept of the isochron is fixed based on some external information. Anchored isochrons can be very useful in cases where the data are insufficiently spread out to constrain both the radiogenic and non-radiogenic isotopic composition.
This paper addresses both of these issues by extending a maximum likelihood algorithm that was first proposed by Titterington and Halliday (1979). The new algorithm offers the ability to attribute any excess dispersion to either the inherited component (“model 3a”) or diachronous closure of the isotopic system (“model 3b”). It provides an opportunity to anchor isochrons to either a fixed non-radiogenic composition or a fixed age. Last but not least, it allows the user to attach meaningful analytical uncertainty to the anchor. The new method has been implemented in IsoplotR for immediate use in , , , , , , , , , and U–Th–He geochronology.
- Article
(1778 KB) - Full-text XML
- BibTeX
- EndNote





Isochrons are mixing lines between radiogenic and inherited isotopic endmembers. They are an essential component of radiometric geochronology and exist in several forms. Sections 1–7 of this paper will deal with the simple case of “ isochrons”, which apply to geochronometers that are based on the decay of a single radioactive parent nuclide (P; e.g. 87Rb, 40K, 147Sm) to a particular daughter nuclide (D; e.g. 87Sr, 40Ar, 143Nd). Sections 8 and 9 will discuss and isochrons, respectively. These are based on the paired decay of two parents (238U and 235U) to two daughters (206Pb and 207Pb, respectively) and require linear regression in two or three dimensions.
isochrons come as two types. “Conventional” isochrons are straight-line relationships of the following kind:
where i is the aliquot number (), d is a non-radiogenic sister isotope of D, is the inherited component, λ is the decay constant, and t is the time elapsed since isotopic closure. A full list of definitions is provided in Appendix A. “Inverse” isochrons are obtained by permuting P, D, and d:
The choice between conventional and inverse isochrons depends on the relative precision of the mass spectrometer measurements. Inverse isochrons are preferred if d≪D. Otherwise, conventional isochrons are fine (Li and Vermeesch, 2021).
Equations (1) and (2) can be recast into a generic linear form:
Table A1 maps the parameters of this generic equation to the parameters of Eqs. (1) and (2) as well as subsequent variants thereof. Equation (3) is usually solved by York et al. (2004) regression (hereafter simply referred to as “York regression”). York regression uses a least-squares algorithm to estimate the intercept (a) and slope (b) of the isochron line from an n×5 table of paired isotopic ratio measurements, along with their standard errors and their error correlations.
Although this paper will use the York parameters a and b to fit the isochron, all results will be presented in terms of the geologically more meaningful inherited endmember ratio and radiogenic endmember ratio , where and for conventional isochrons and and for inverse isochrons (Li and Vermeesch, 2021).
The most accurate and precise results are obtained from samples that are evenly spread along the isochron line, spanning the entire range of values from the inherited to the radiogenic endmember. Unfortunately, this condition is not always fulfilled. It is not uncommon for most or all aliquots in a sample to cluster together at one point along the isochron, making it difficult to accurately estimate the endmember compositions. For example, no precise isochron ages can be obtained from samples whose radiogenic daughter component is dwarfed by the inherited daughter component. Conversely, the composition of the inherited component cannot be precisely estimated in extremely radiogenic samples. Finally, when the data cluster together in the middle, then neither endmember component can be reliably determined (Fig. 1).
Sometimes, such poorly constrained isochrons can be fixed using external information. For example, if the composition of the inherited component is known through some independent means (e.g. by analysing a cogenetic mineral that is naturally poor in P and rich in D and d), then this information can be used to anchor the isochron. Anchoring reduces the number of unknown parameters by 1, benefitting numerical stability and precision. Conversely, if the age of the sample is known, then the inherited component can be estimated by anchoring to the radiogenic endmember.
There is currently no formally documented way to anchor York regression. A commonly used “hack” is to add an extra data point with infinite precision representing either the inherited or radiogenic endmember component. However, this hack does not provide a satisfactory mechanism to assign uncertainty to the anchor. This paper solves that problem. Section 2 introduces a maximum likelihood formulation of York regression, which is amenable to anchoring with uncertainty. Section 3 shows how this formulation can be used to model “errorchrons” that are overdispersed with respect to the analytical uncertainties.
Section 4 provides further details about the implementation of maximum likelihood regression, which can attribute overdispersion to either the intercept (“model 3a”) or slope (“model 3b”) of the linear fit. It turns out that model 3b is computationally more challenging than model 3a. Section 5 shows how this issue can be avoided by inverting and flipping the isochron axes.
Section 6 shows how anchored isochron regression represents a trivial special case of the maximum likelihood algorithm. Section 7 attaches two different geological interpretations to the uncertainty of isochron anchors. These two interpretations lead to two different fit models (“model 1” and “model 3”, which are so named for historical reasons). Sections 8 and 9 apply the same logic to and isochrons, respectively. Finally, Sect. 10 shows how the new algorithms can be used within the IsoplotR software package.
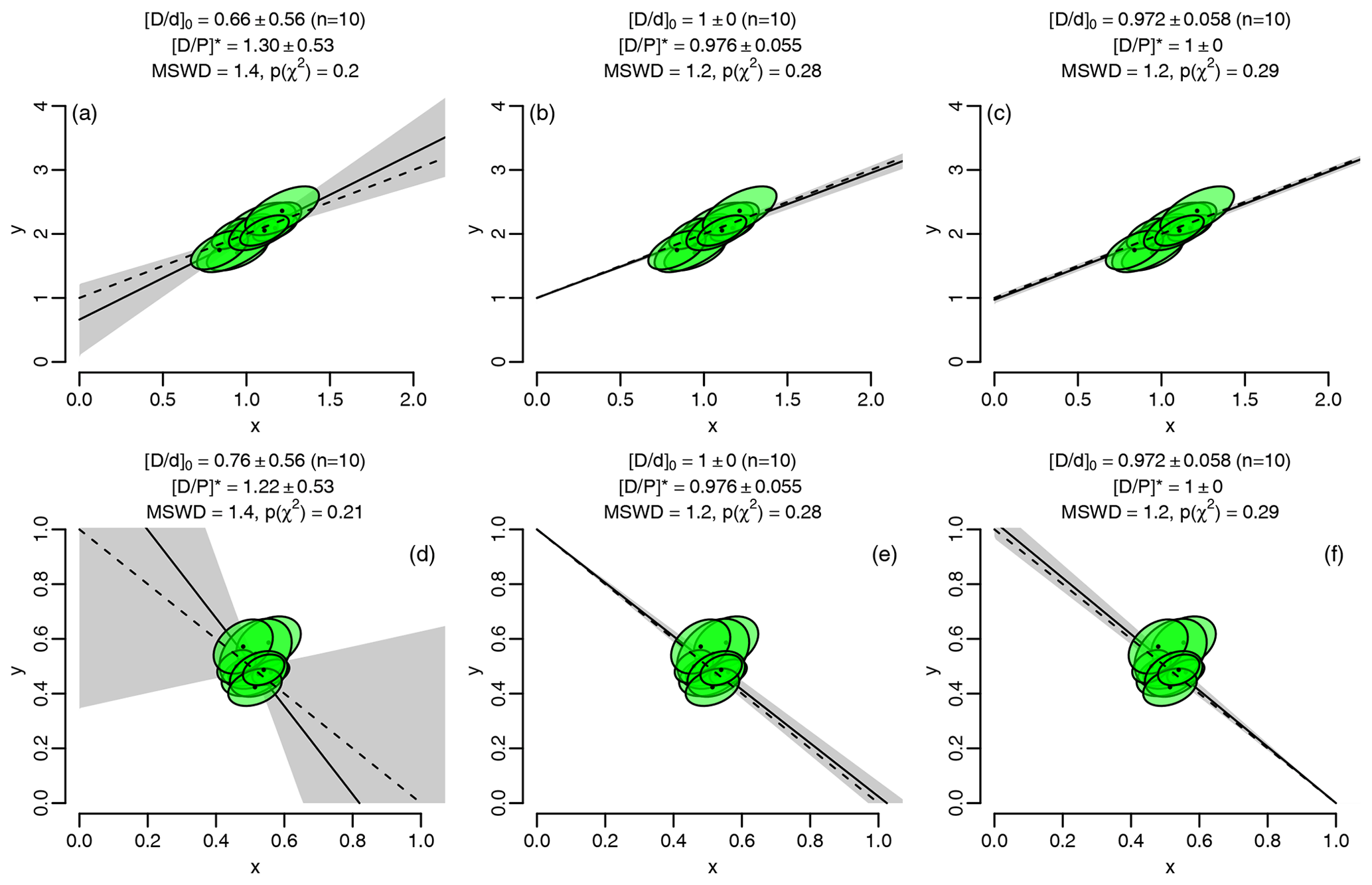
Figure 1 isochron diagrams for a synthetic dataset generated using the procedures of Appendix B. The true slope and intercept are a=1 and b=1 for the conventional isochrons (a–c) and a=1 and for the inverse isochrons (d–f). These parameter values correspond to . The true trends are shown as dashed lines and the estimated trends as solid lines, with 95 % confidence envelopes shown in grey. The estimated parameter values are shown above the panels. Unconstrained isochron regression (a, d) yields imprecise and inaccurate results. Fixing the inherited component (b, e) or the radiogenic component (c, f) greatly improves both aspects of the fit.
York et al. (2004) use the method of least squares to fit the general problem of weighted regression with correlated uncertainties in both variables. Titterington and Halliday (1979) obtained identical results using the method of maximum likelihood. The latter approach offers greater flexibility than least squares and will be used in the remainder of this paper.
The method of maximum likelihood is a standard statistical technique to estimate the parameters of a probability distribution from a set of measurements. In the case of two-dimensional isochron regression, the parameters are the intercept a, the slope b, and the true (but unknown) xi values. The data are the Xi and Yi measurements along with their assumed uncertainties and error correlations (see Appendix A for a full list of definitions). For a dataset of n aliquots, there are 2n measurements (n Xi values and n Yi values) and n+2 parameters (a, b, and n xi values). That leaves “degrees of freedom” to estimate the parameters.
This overconstrained problem can be solved by minimizing the paired differences (“residuals”) between the true xi and yi values (where ) and between the measured Xi and Yi values.
To make the problem tractable, the vector of residuals Δi is assumed to be drawn from a bivariate normal distribution with zero mean and covariance matrix Σi:
and
The product of the normal probabilities for all the aliquots (from ) is called the “likelihood” of the parameters given the data. Maximizing this number produces the most accurate possible parameter estimates , , and . Alternatively, and equivalently, the same estimates can be obtained by maximizing the logarithm of the likelihood. This is the preferred approach as it improves numerical stability and facilitates the estimation of the parameter uncertainties. The log-likelihood function can be formally defined as
This formulation allows for correlated uncertainties between the variables ( in Eq. 5) but not between aliquots ( if i≠j). Daëron and Vermeesch (2023) discuss the generalized case of “omnivariant” regression, where this requirement has been relaxed and Eq. (6) is replaced with a single matrix expression.
The degree to which the residuals Δi are consistent with the assumed analytical uncertainties Σi can be assessed using a chi-square test and the MSWD parameter. Readers who are not familiar with these concepts are referred to Appendix C for details. Isochrons that exhibit significant overdispersion with respect to the analytical uncertainties are colloquially referred to as errorchrons. Whether it is right to use such a pejorative term for this common phenomenon is debatable (Schaen et al., 2021). Four approaches may be used to deal with errorchrons.
- Model 1.
-
Inflate the analytical uncertainties by a factor .
- Model 2.
-
Ignore the analytical uncertainties and replace York regression with orthogonal regression or a similar technique. This approach will not be discussed further in this paper.
- Model 3.
-
Quantify the dispersion as an additional free parameter. There are two options for doing so.
-
Model 3a. Attribute the excess dispersion to variability of the inherited component and, hence, the isochron intercept. For conventional isochrons, this means that the true isotopic ratios of the cogenetic aliquots do not belong to a single isochron line but to a family of parallel isochron lines whose intercepts are normally distributed (Titterington and Halliday, 1979). The standard deviation of this normal distribution (σa) can be used to quantify the dispersion of the data around the “central” isochron line.
-
Model 3b. Attribute the excess dispersion to diachronous closure of the isotopic system. This mechanism produces families of conventional isochrons that share a common intercept but differ in their slopes. Again, the distribution of the slopes can be assumed to follow a normal distribution, with mean b and standard deviation σb. The latter value can be used to quantify the dispersion of the data, which in this case captures the degree of diachroneity.
-
Model 3a isochron regression can be formalized by modifying Eq. (4) as follows:
The dispersion parameter σa can be estimated (as ) by incorporating it into the covariance matrices:
The equivalent expressions for model 3b regression are
and
respectively.
Three specific cases of Eq. (6) are of interest in the present discussion.
Model 1.
Model 3a.
Model 3b.
Note that the (logged) determinant of the covariance matrices is not included in the constant for model 3 fits because Σa,i and Σb,i are both functions of x, whereas Σi is not. ℒℒ can be numerically maximized using an iterative two-step procedure. For model 1 regression, the first step maximizes to find x for any pair of a and b values. The second step repeats the first step for different values of a and b until the overall optimum is reached.
This procedure can easily be adapted to model 3 regression by adding σa or σb to the unknown parameters. It works well for model 3a, where the first step has a direct solution. However, it is slow for model 3b regression, in which finding x requires an additional level of iteration. See Appendix D for further details. Fortunately, in practice model 3b is rarely or never needed for geochronology, as explained next.
For inverse isochrons, model 3b regression does not actually provide any useful information. Unlike conventional isochrons, whose chronological information is contained in the slope, the chronological information of inverse isochrons is contained in their horizontal intercept. This information can be unlocked by flipping the axes of the isochron diagram around, inverting the isochron, and treating the ratio as the dependent variable. Applying model 3a regression to the flipped data yields a dispersion estimate σa that can be used to quantify the age dispersion.
The same trick can be used to estimate the slope uncertainty of a conventional isochron. A pragmatic way to avoid the slow convergence rate of model 3b regression is to invert the isochron, flip the dependent and independent variables around, invert the isochron a second time, and carry out a model 3a regression on the transformed data. The resulting σa estimate can be converted to a σb estimate:
Figure 2 applies model 3 regression to two synthetic Ar–Ar datasets with a non-radiogenic ratio of 400 and an age of 100 Ma. The dataset of Fig. 2a exhibits overdispersion of the y intercept ([40Ar 36Ar), whereas the dataset of Fig. 2b is overdispersed in the x intercept (t=100 Ma, σt=10 Ma). In both cases, the maximum likelihood algorithm has retrieved the correct solution from the noisy data.
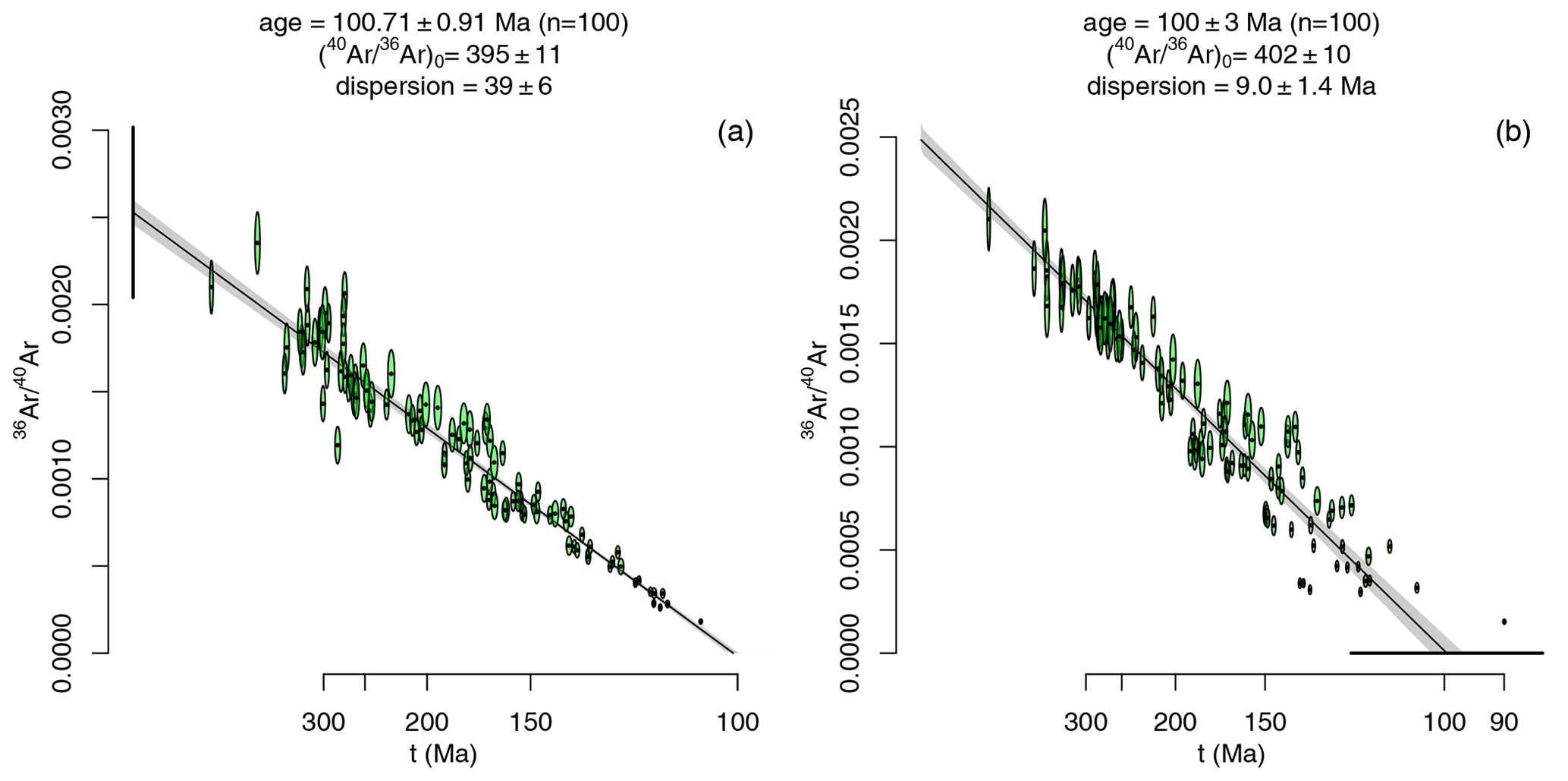
Figure 2Model 3 regression of two synthetic Ar–Ar datasets. (a) Model 3a regression through 100 randomly drawn aliquots from an isochron with a true non-radiogenic ratio of 400±40 (1σ) and a true age of 100 Ma; (b) model 3b regression through 100 aliquots from an isochron with a true non-radiogenic ratio of 400 and a true age of 100±10 Ma (1σ). Error bars on the y and x axis show the overdispersion at 95 % confidence.
Anchored isochron regression requires just a trivial modification of the maximum likelihood algorithm. It suffices to treat the anchored parameter as data. For example, the slope and intercept of a model 1 isochron can be anchored by maximizing and , respectively. Note that these calculations assume that the anchor is known exactly. This is reflected in the zero uncertainties of the non-radiogenic component in Fig. 1b and e and of the radiogenic components in Fig. 1c and f. Such absolute certainty is unrealistic in the noisy world of geology. Section 7 introduces two ways to formally account for uncertainty in anchored isochron regression.
When assigning uncertainty to statistical parameters, it is important to clearly define the meaning of this uncertainty. In the case of anchored isochron regression, the uncertainty of the intercept or slope can carry two meanings. For example, when the intercept of an isochron is anchored at a value , this can mean either of the following.
- Model 1.
-
The data are underlain by a single isochron whose intercept is only approximately known, with a most likely value of and a precision (standard error) of .
- Model 3.
-
The data were drawn from a family of isochron lines whose intercepts follow a normal distribution with mean and standard deviation .
These two different approaches can be implemented by replacing the log-likelihood functions of Eq. (13) with the following.
The equivalent expressions for anchored slopes with uncertainty are as follows.
Note that model 1 treats the slope and intercept as unknowns, so their maximum likelihood estimates generally do not equal the anchored values and . However, the smaller and are relative to and , the closer that and are to and . In contrast, anchored model 3 regression fixes the dispersion of the anchored parameters so that for anchored intercepts, whereas for anchored slopes.
Figure 3 applies the two approaches to the synthetic dataset of Fig. 1 using anchors of and (1σ). As expected, models 1 and 3 produce slightly different outcomes, with model 1 resulting in and estimates that are slightly different than the anchored values, whereas model 3 reproduces the anchors exactly. The model 3 fits produce more precise estimates for the unanchored quantities. This reflects the fact that some of the uncertainty in the isochron is captured by the dispersion parameter, which is absent from the model 1 fit.
Model 3 partitions the analytical and geological uncertainty between the standard errors of and on the one hand and the dispersion parameter on the other hand. It is not easy to visualize this partitioned uncertainty. Figure 3 uses a grey confidence envelope to show the analytical uncertainty and a black error bar to visualize the geological dispersion. Together these two items represent the total uncertainty budget.
It is, of course, also possible to treat the dispersion parameter as an unknown by maximizing or . Section 9 will give an example of this in the context of U–Pb geochronology.
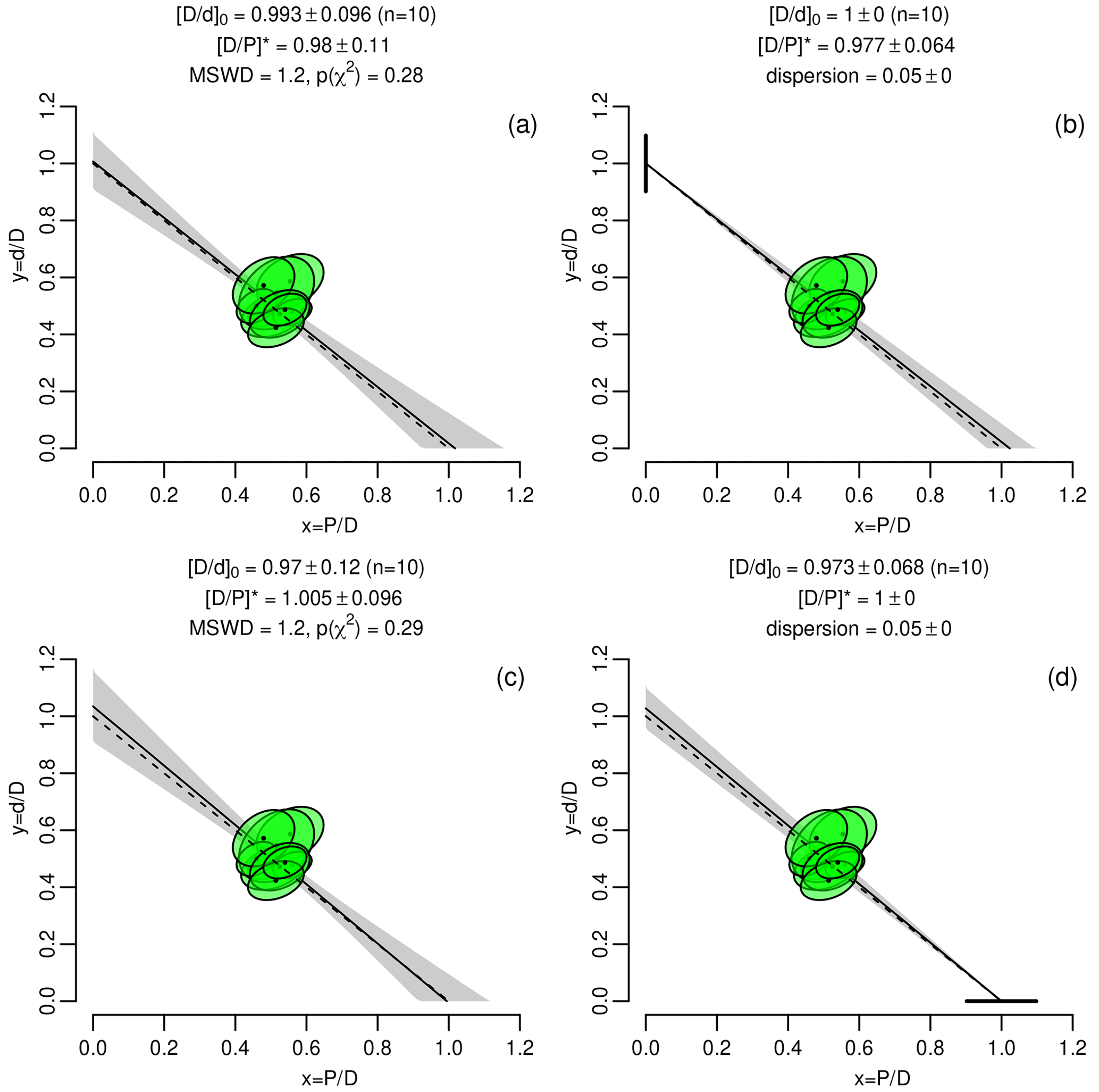
Figure 3Anchored isochrons for the data of Fig. 1, shown on inverse isochrons. Panels (a) and (b) anchor the non-radiogenic endmember composition to (1σ). Panels (c) and (d) anchor the radiogenic endmember composition to (1σ). Panels (a) and (c) use model 1 isochron regression, whereas panels (b) and (d) use model 3. Note how the estimated values for and are exactly the same as the anchored values for model 3 but not for model 1. The vertical error bar in panel (b) and the horizontal error bar in panel (d) represent the fixed dispersion of the vertical and horizontal intercept, respectively.
The method is based on the paired decay of two radioactive parents P1 and P2 (238U and 235U) to two daughters D1 and D2 (206Pb and 207Pb, respectively) in the presence of a non-radiogenic sister isotope d (204Pb). This gives rise to the following implicit age equation:
where λ1 and λ2 are the decay constants of P1 and P2, respectively, and is constant. Equation (17) can be recast into the generic form of Eq. (3) to form a “ isochron” using the mapping of Table A1. This gives rise to conventional ( vs. ) and inverse ( vs. ) isochrons.
Unlike inverse isochrons, which are characterized by negative slopes, inverse isochrons have positive slopes. There is perfect symmetry between conventional and inverse isochrons in the sense that the intercept of a conventional isochron equals the slope of an inverse isochron and vice versa. This slightly changes and, in fact, simplifies the procedure for anchored isochron regression.
There is no need for flipped isochron regression of data. Instead, all possible scenarios can be handled by straightforward model 1 and model 3a regression. Isochrons can be anchored to the non-radiogenic component in conventional isochron space and to the radiogenic component in inverse isochron space.
The method, like the method, is based on the paired decay of 238U to 206Pb and of 235U to 207Pb. The two chronometers can be treated separately and plotted as isochrons. These two-dimensional isochrons can be anchored to the radiogenic and non-radiogenic composition using the methods described in Sects. 2–7.
Alternatively, the two ingrowth equations can also be coupled, forming a three-dimensional “total isochron”. This problem can be solved using the method of maximum likelihood (Ludwig, 1998). There is just one important difference between this solution and the York-like algorithm of Sect. 2. York regression is formulated in terms of a generic intercept (a) and slope (b). In contrast, the “Ludwig” algorithm is formulated in terms of the actual non-radiogenic (=α) and (=β) ratio, as well as the age (t) of the system.
It is relatively straightforward to generalize the concept of model 3 regression to total isochrons when the dispersion is attributed to the isochron age. However, it is not immediately clear how to do the same for the non-radiogenic composition because this would require partitioning the dispersion between the α and β parameters. This paper will not attempt to answer this question. Instead, let us conclude the technical discussion by shifting to a far more common type of data.
Most published studies do not report 204Pb because this nuclide is rare and difficult to measure. Instead, “semitotal ” regression is done in Wetherill or Tera–Wasserburg concordia space, which are akin to conventional and inverse isochron space, respectively. In the absence of a non-radiogenic sister isotope of Pb, the isochron is then redefined as a mixing line between an inherited ratio and the radiogenic and ratios.
The semitotal problem can be cast into a maximum likelihood format by replacing Eq. (4) with
where Xi and Yi are the measured and ratios of the ith aliquot, respectively, and xi is the true ratio of the ith aliquot, whilst and . Equation (19) can be solved using the same recipe as the York reformulation of Sects. 2–7, with the caveat that the isochron terminates on the concordia line at the composition corresponding to t.
Figure 4 shows a model 3a anchored semitotal isochron in Tera–Wasserburg space. The true age for this synthetic dataset is 1500 Ma. The unconstrained model 1 isochron produces an imprecise isochron age of 1491±100 Ma, which is improved to 1504±38 Ma by anchoring to . Just like the isochrons of Fig. 3, the uncertainty budget for the isochrons of Fig. 4 is partitioned between the analytical and geological dispersion, where the latter is treated as a free parameter with a maximum likelihood estimate of .
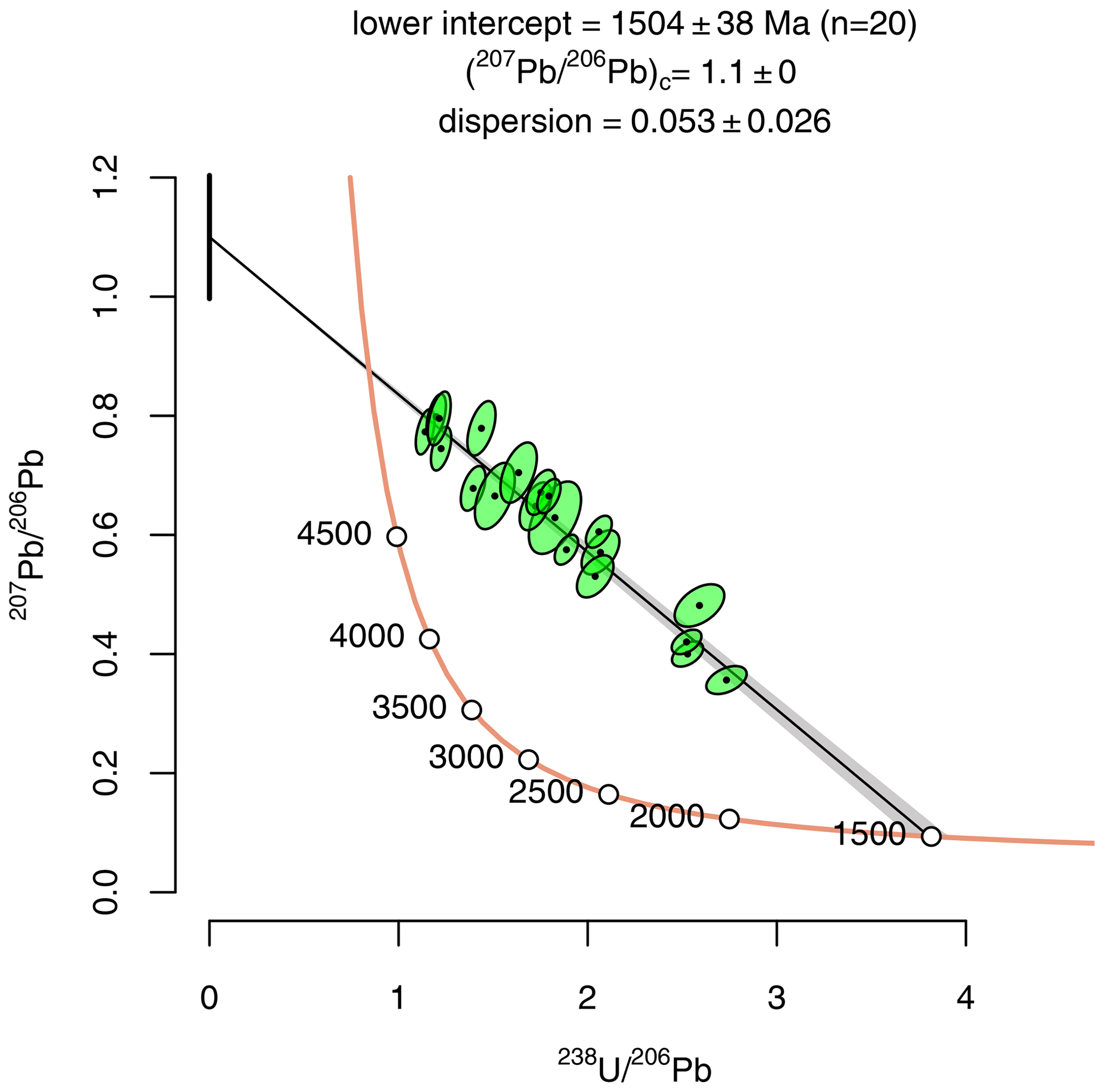
Figure 4Model 3a semitotal isochron for a synthetic dataset with a true age t=1500 Ma, anchored to with the dispersion parameter treated as a free parameter.
All the algorithms presented in this paper have been implemented in the free and open geochronological toolbox IsoplotR (Vermeesch, 2018). The ability to fit isochrons with models 1, 2, and 3 dates back to IsoplotR's first public release. Versions 2.1 and 5.2 added model 1 anchors to isochrons without and with uncertainty, respectively. Anchored York regression and model 3 anchors with uncertainty were added to IsoplotR 6.0. These functions can be accessed via the GUI or from the command line.
In the GUI, anchored regression is available from the “isochron” menu (so not from the “concordia” menu for data). The relevant settings can be selected from the “options” menu and should be self-explanatory. Moving on to the R console, use a built-in dataset to illustrate the command-line functionality and start with an unanchored inverse isochron fit using York regression.
library(IsoplotR) attach(examples) isochron(ArAr)
Carry out model 3a isochron regression anchored to a variable initial ratio of 300±5 (1σ).
settings('iratio','Ar40Ar36',300,5)
isochron(ArAr,anchor=1,model=3,taxis=TRUE)
Here, settings(…) is used to change the non-radiogenic argon composition, anchor=1 fixes the isochron to the inherited component, model=3 tells IsoplotR to assign the dispersion to the reported uncertainty of the atmospheric ratio, and taxis=TRUE changes the x axis to a timescale (as in Fig. 2).
Finally, carry out model 3b isochron regression anchored to a radiogenic composition that was set at 62±1 Ma (1σ).
isochron(ArAr,anchor=c(2,62,1),
model=3,taxis=TRUE) The dispersion can be changed to a free parameter by setting the third element of the anchor argument to a non-positive value. Documentation for additional options and settings can be accessed from the console using the help(isochron) or ?isochron commands.
This paper builds on previous work by McIntyre et al. (1966), Titterington and Halliday (1979), and Ludwig (2012). McIntyre et al. (1966) introduced the concept of model 3 isochron regression, attributing the excess dispersion of errorchrons to variability of the inherited component. This approach is implemented in Isoplot (Ludwig, 2012) and is referred to as model 3a regression in this paper. Note that the McIntyre et al. (1966) definition of model 2 regression differs from that of Ludwig (2012). It is more akin (but not identical) to the approach of Sect. 3.
Titterington and Halliday (1979) recast the model 3 algorithm of McIntyre et al. (1966) in a maximum likelihood framework. This paper extends the maximum likelihood approach to a second type of geological scenario, in which excess dispersion of the data around the isochron is not attributed to the inherited component but to the radiogenic component. This approach is referred to as model 3b regression.
The maximum likelihood formulation of isochron regression can also be used to anchor isochrons to either the inherited or the radiogenic component and to assign geologically meaningful uncertainty to the anchor. In reality it is possible that some samples are affected by both mechanisms so that different aliquots of the same sample differ in their initial ratios as well as the timing of their isotopic closure. Unfortunately, it is not possible to simultaneously capture both types of dispersion using the algorithms of this paper.
The difference between model 1 and model 3 regression represents two contrasting views of geological reality. The model 1 approach assumes that the isotopic composition of minerals represents discrete components recorded at distinct events. In contrast, model 3 isochrons represent a “fuzzier” reality, in which the initial composition or timing of isotopic closure is allowed to vary within a rock. Under the latter model, the concept of an errorchron no longer makes sense.
| P | a radioactive parent (e.g. 87Rb) |
| D | the radiogenic daughter of P (e.g. 87Sr) |
| d | a non-radiogenic sister isotope of D (e.g. 86Sr) |
| a, b, xi, yi | the true (but unknown) values of the intercept, slope, and isotopic ratio of the ith aliquot (out of n aliquots) from a sample |
| , , , | the estimated values of a, b, xi, and yi, respectively |
| Xi, Yi | the measured values of xi and yi, respectively |
| s[Xi], s[Yi], s[Xi,Yi] | the standard errors and covariance of Xi and Yi |
| , | the residuals of the data around the best-fit line |
| Σi | the 2×2 covariance matrix of Xi and Yi |
| x, y, X, Y, Σ | arrays and sets containing all n xi, yi, Xi, Yi, and Σi values |
All uncertainties in this paper are reported as 95 % confidence intervals except if noted otherwise.
Table A1Assignment of the isotopic ratios for and isochrons to the generic parameters of Eq. (3).

The synthetic data in Figs. 1 and 3 were generated as follows.
-
Generate x by drawing 10 random numbers from a logit-normal distribution where the mean and standard deviation of the logits are 0 and 15, respectively.
-
Generate y by plugging x into Eq. (3) with .
-
Turn the resulting 10 pairs of {xi,yi} values into 10 trios of values where di is a random number between 100 and 500.
-
Use each of the values obtained in the previous step as parameters for a Poisson experiment.
-
Use the Poisson values obtained in the previous step to form 10 pairs of X and Y measurements and their (correlated) uncertainties.
-
Add some excess dispersion by shrinking the uncertainties by 20 %.
Note that this procedure fits the definition of a model 1 isochron, even though panels (b) and (d) of Fig. 3 use the resulting data to illustrate model 3 regression. The synthetic data in Figs. 2 and 4 are generated using a slightly different algorithm that simulates model 3a and 3b overdispersion. This modified procedure uses steps 1 and 3–4 of the procedure for Fig. 1 whilst replacing step 2 with a random effects model, in which a and b are drawn from random normal distributions with standard deviations corresponding to the dispersion parameters (10 % for Fig. 2a and 5 % for Fig. 4) and (10 % for Fig. 2b).
Whether a dataset is overdispersed with respect to the analytical uncertainties can be formally assessed using the chi-square statistic and test. To this end, calculate the χ2 statistic using the sum of squares term of Eq. (6).
If analytical uncertainty is the only source of dispersion in the dataset, then χ2 is expected to follow a chi-square distribution with n−2 degrees of freedom (, or, for anchored regression, ). This is called the “null distribution”. The probability of observing a value greater than χ2 under this distribution is called the p value. A p value cutoff of 0.05 is generally used to distinguish isochrons (p≥0.05) from errorchrons (p<0.05). Dividing Eq. (C1) by the number of degrees of freedom produces a “reduced chi-square statistic”, which is known to geologists as an MSWD (McIntyre et al., 1966).
In the absence of overdispersion and for sufficiently large samples (n>20), the expected null distribution of the MSWD is approximately normal with a mean of 1 and a standard deviation (Wendt and Carl, 1991). This information can be used as an alternative way to test the null hypothesis.
Section 4 describes how the log-likelihood functions of Eq. (13) can be maximized in a two-step process: (1) find the xi values that maximize ℒℒ for any pair of a and b values, and (2) search the space of a and b values until the overall maximum is found. For model 1 regression, the first step has a direct solution. Some shorthand notation for the inverse of the covariance matrix Σi is introduced:
where . The fitted points xi can be found by solving
which yields
The same approach can be used for model 3a regression (with ). However, it does not work for model 3b isochrons because when i≠j. Therefore, the xi values are interdependent and cannot be solved separately. Although it is possible to jointly optimize the entire x vector, this takes considerably longer than model 1 and model 3a regression. Fortunately, as explained in Sect. 5, model 3b regression can be reformulated in terms of the model 3a algorithm.
IsoplotR is available from CRAN (https://CRAN.Rproject.org/package=IsoplotR, last access: 15 July 2024) and Zenodo (https://doi.org/10.5281/zenodo.11114310; Vermeesch and Lloyd, 2024).
This paper only uses synthetic data, which were generated using the procedures outlined in Appendix B.
The author is a member of the editorial board of Geochronology. The peer-review process was guided by an independent editor, and the author also has no other competing interests to declare.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The author would like to thank reviewers Donald Davis and John Rudge for suggesting to expand the discussion of model 3 regression and for checking the equations. This work was completed during a sabbatical stay at the Institute of Geology and Geophysics, Chinese Academy of Sciences, which was supported by the CAS President's International Fellowship Initiative (PIFI). The author would like to thank Xian-Hua Li of IGG-CAS and Yang Li of Peking University for hosting him at IGG-CAS. He would also like to thank IsoplotR users Guilhem Hoareau (CNRS, France), Shitou Wu (IGG-CAS, China), and Stijn Glorie (Adelaide, Australia) for discussing the utility of anchored isochrons and moving this feature up the priority list for IsoplotR.
This research has been supported by the Natural Environment Research Council (grant no. NE/T001518/1).
This paper was edited by Noah M McLean and reviewed by Donald Davis and John Rudge.
Daëron, M. and Vermeesch, P.: Omnivariant generalized least squares regression: Theory, geochronological applications, and making the case for reconciled Δ47 calibrations, Chem. Geol., 647, 121881, https://doi.org/10.1016/j.chemgeo.2023.121881, 2023. a
Li, Y. and Vermeesch, P.: Short communication: Inverse isochron regression for Re–Os, K–Ca and other chronometers, Geochronology, 3, 415–420, https://doi.org/10.5194/gchron-3-415-2021, 2021. a, b
Ludwig, K. R.: On the treatment of concordant uranium-lead ages, Geochim. Cosmochim. Ac., 62, 665–676, https://doi.org/10.1016/S0016-7037(98)00059-3, 1998. a
Ludwig, K. R.: User's manual for Isoplot 3.75: a geochronological toolkit for Microsoft Excel, Berkeley Geochronology Center, 5, https://doi.org/10.5281/zenodo.12744084, 2012. a, b, c
McIntyre, G. A., Brooks, C., Compston, W., and Turek, A.: The Statistical Assessment of Rb-Sr Isochrons, J. Geophys. Res., 71, 5459–5468, 1966. a, b, c, d, e
Schaen, A. J., Jicha, B. R., Hodges, K. V., Vermeesch, P., Stelten, M. E., Mercer, C. M., Phillips, D., Rivera, T. A., Jourdan, F., Matchan, E. L., Hemming, S. R., Morgan, L. E., Kelley, S. P., Cassata, W. S., Heizler, M. T., Vasconcelos, P. M., Benowitz, J. A., Koppers, A. A. P., Mark, D. F., Niespolo, E. M., Sprain, C. J., Hames, W. E., Kuiper, K. F., Turrin, B. D., Renne, P. R., Ross, J., Nomade, S., Guillou, H., Webb, L. E., Cohen, B. A., Calvert, A. T., Joyce, N., Ganerød, M., Wijbrans, J., Ishizuka, O., He, H., Ramirez, A., Pfänder, J. A., Lopez-Martínez, M., Qiu, H., and Singer, B. S.: Interpreting and reporting geochronologic data, Bulletin, 133, 461–487, https://doi.org/10.1130/B35560.1, 2021. a
Titterington, D. M. and Halliday, A. N.: On the fitting of parallel isochrons and the method of maximum likelihood, Chem. Geol., 26, 183–195, 1979. a, b, c, d
Vermeesch, P.: IsoplotR: a free and open toolbox for geochronology, Geosci. Front., 9, 1479–1493, 2018. a
Vermeesch, P. and Lloyd, J. C.: pvermees/IsoplotR: 6.2 (6.2), Zenodo [code], https://doi.org/10.5281/zenodo.11114310, 2024. a
Wendt, I. and Carl, C.: The statistical distribution of the mean squared weighted deviation, Chem. Geol.: Isotope Geoscience Section, 86, 275–285, 1991. a
York, D., Evensen, N. M., Martínez, M. L., and De Basabe Delgado, J.: Unified equations for the slope, intercept, and standard errors of the best straight line, Am. J. Phys., 72, 367–375, 2004. a, b
- Abstract
- Introduction
- Maximum likelihood formulation of York regression
- Dealing with overdispersion
- Specific cases
- Flipped isochron regression
- Anchored isochron regression
- Accounting for anchor uncertainty
- isochrons
- isochrons
- Implementation in IsoplotR
- Conclusions
- Appendix A: Definitions
- Appendix B: Data
- Appendix C: Testing overdispersion
- Appendix D: Further details about the maximum likelihood solution
- Code availability
- Data availability
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Maximum likelihood formulation of York regression
- Dealing with overdispersion
- Specific cases
- Flipped isochron regression
- Anchored isochron regression
- Accounting for anchor uncertainty
- isochrons
- isochrons
- Implementation in IsoplotR
- Conclusions
- Appendix A: Definitions
- Appendix B: Data
- Appendix C: Testing overdispersion
- Appendix D: Further details about the maximum likelihood solution
- Code availability
- Data availability
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References